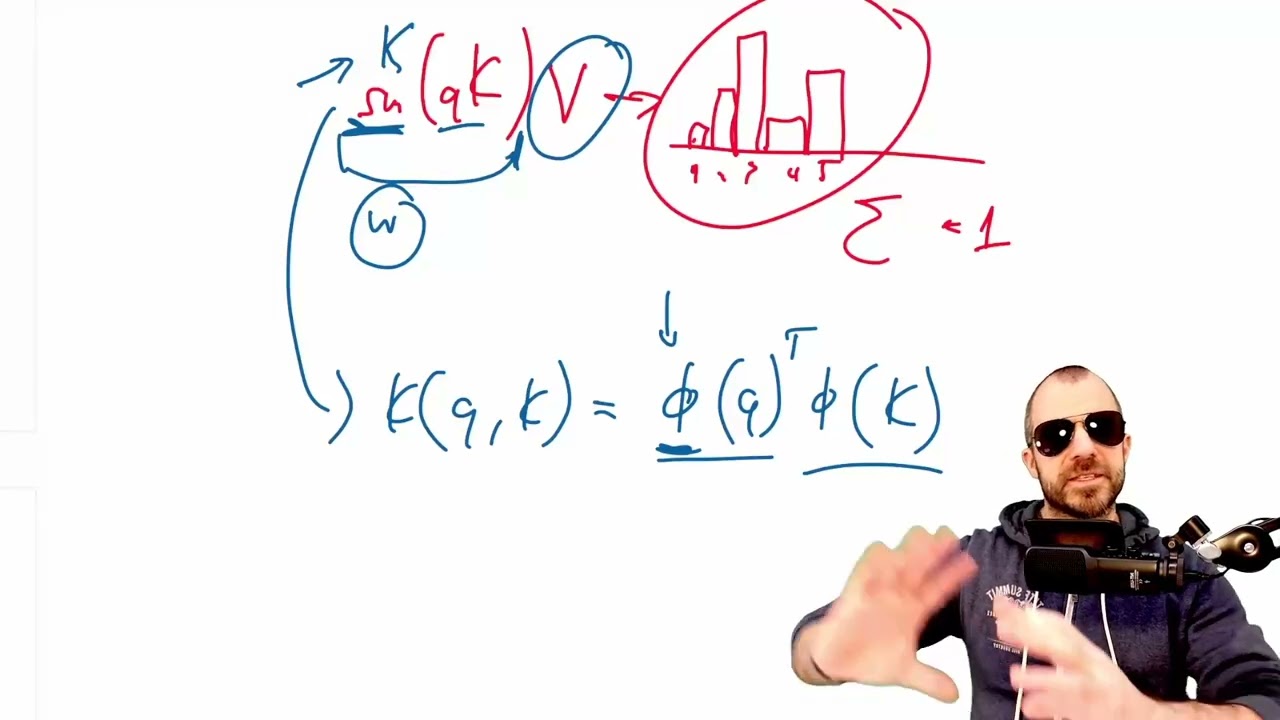Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Автор: Yannic Kilcher
Загружено: 2024-04-24
Просмотров: 59882
Описание:
Google researchers achieve supposedly infinite context attention via compressive memory.
Paper: https://arxiv.org/abs/2404.07143
Abstract:
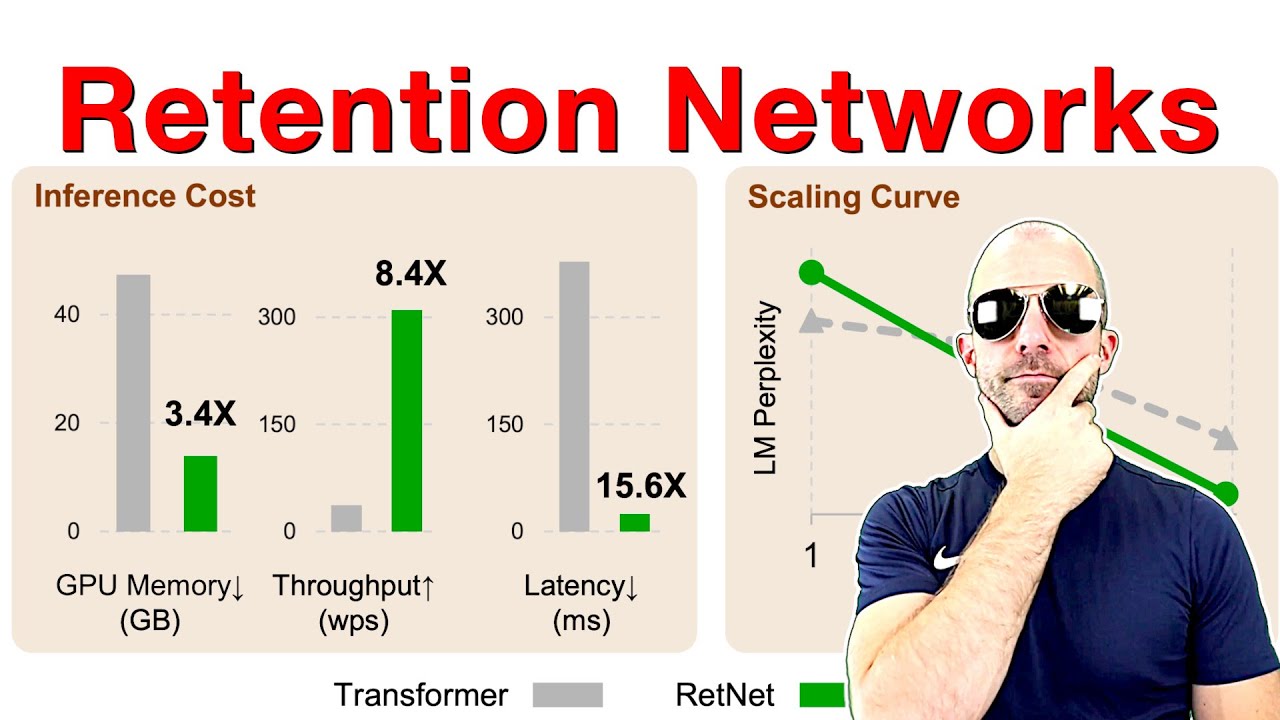
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Authors: Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: / yannickilcher
Twitter: / ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: / ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: / yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: