Retentive Network: A Successor to Transformer for Large Language Models (Paper Explained)
Автор: Yannic Kilcher
Загружено: 2023-09-12
Просмотров: 102949
Описание:
#ai #retnet #transformers
Retention is an alternative to Attention in Transformers that can both be written in a parallel and in a recurrent fashion. This means the architecture achieves training parallelism while maintaining low-cost inference. Experiments in the paper look very promising.
OUTLINE:
0:00 - Intro
2:40 - The impossible triangle
6:55 - Parallel vs sequential
15:35 - Retention mechanism
21:00 - Chunkwise and multi-scale retention
24:10 - Comparison to other architectures
26:30 - Experimental evaluation
Paper: https://arxiv.org/abs/2307.08621
Abstract:
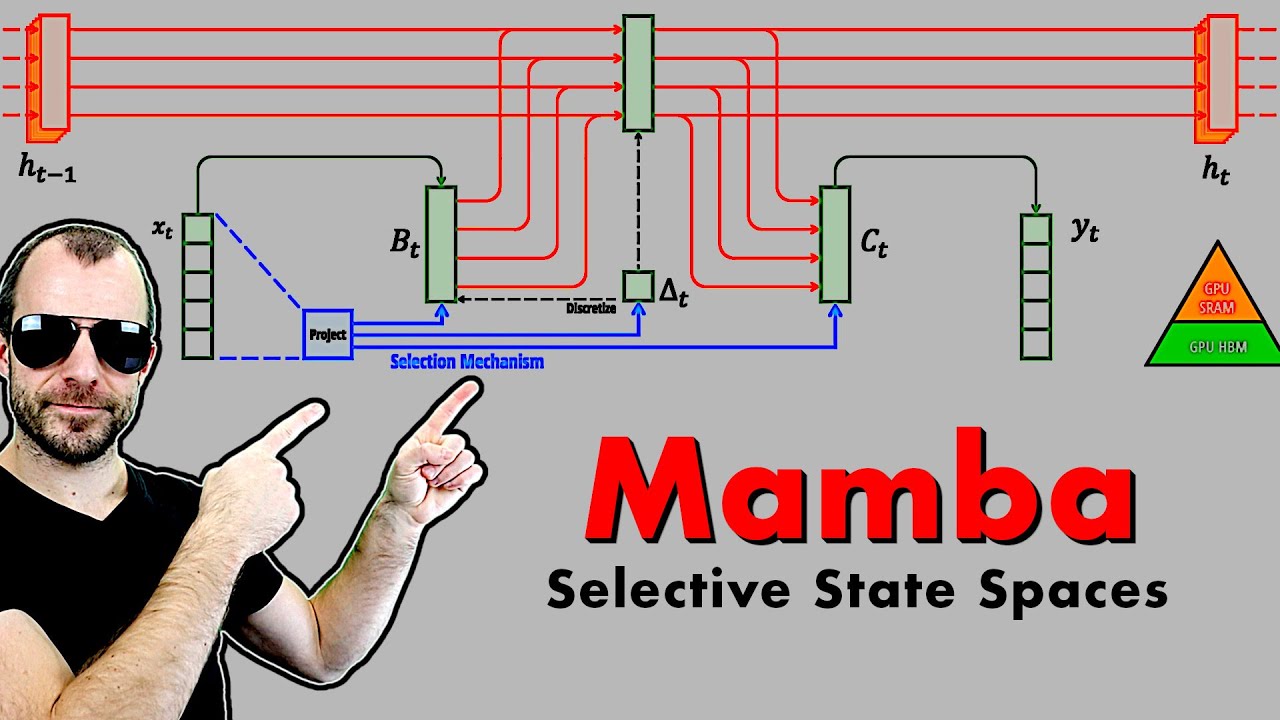
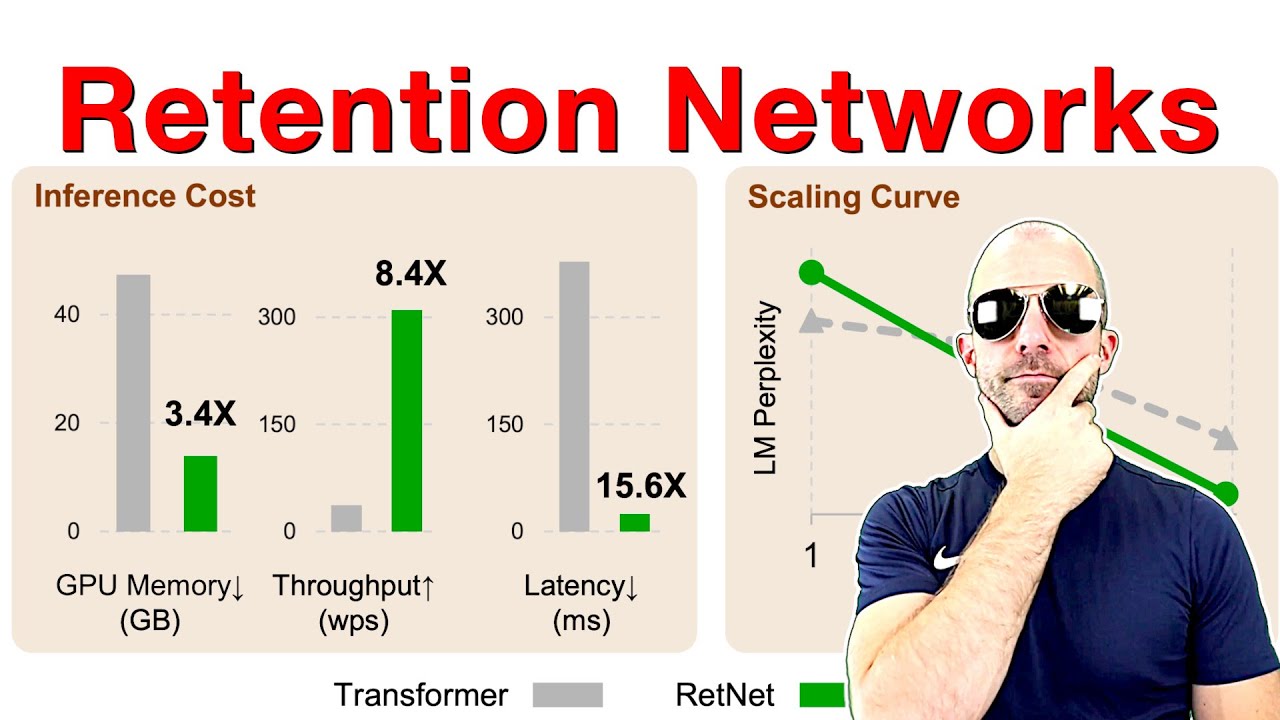
In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost O(1) inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks. Experimental results on language modeling show that RetNet achieves favorable scaling results, parallel training, low-cost deployment, and efficient inference. The intriguing properties make RetNet a strong successor to Transformer for large language models. Code will be available at this https URL.
Authors: Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, Furu Wei
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: / yannickilcher
Twitter: / ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: / ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: / yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



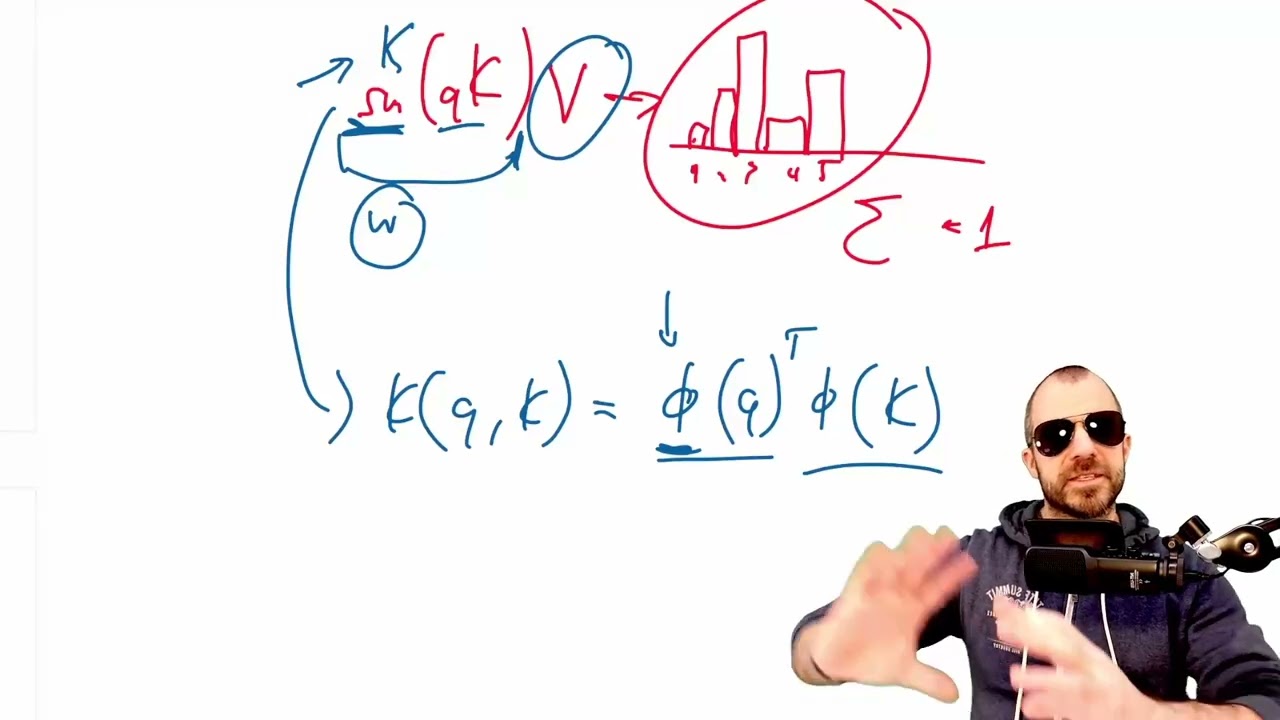




![[GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://imager.clipsaver.ru/bAWV_yrqx4w/max.jpg)





![How DeepSeek Rewrote the Transformer [MLA]](https://imager.clipsaver.ru/0VLAoVGf_74/max.jpg)