LLM'ler Nasıl Eğitilir? Pretraining, SFT, RLHF, DPO ve GRPO, LoRA
Автор: Sami Yusuf Turan
Загружено: 2026-02-20
Просмотров: 21
Описание:
00:00:00 - LLM Eğitim Sürecine Büyük Bakış: Pretraining, SFT ve RLHF
00:02:14 - FineWeb ve Veri Toplama (Data Pipeline): URL Filtreleme ve Temizleme
00:04:18 - NanoGPT, GPT-2 ve GPT-3 Model Büyüklüklerinin Görselleştirilmesi
00:07:34 - Scaling Laws (Ölçekleme Yasaları): Compute, Data ve Parametre İlişkisi
00:09:37 - Chinchilla Law: Parametre Başına Kaç Token Veri Gerekir?
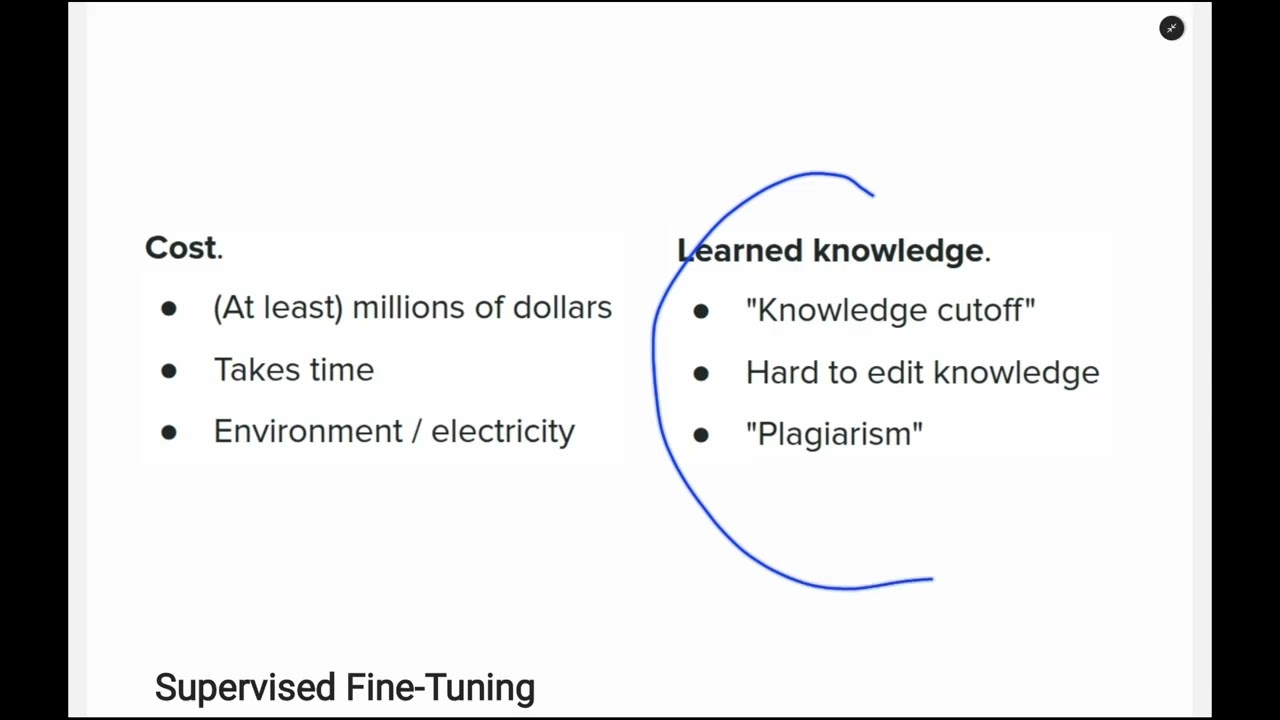
00:11:03 - Pretraining Aşamasının Dezavantajları ve Maliyeti
00:12:12 - Supervised Fine-Tuning (SFT): Modeli Chatbot'a Çevirmek
00:15:20 - LoRA (Low-Rank Adaptation) Nedir? Maliyeti Düşük Fine-Tuning
00:20:05 - QLoRA: Quantization ile Hesaplama Maliyetini Azaltmak
00:20:36 - Preference Alignment: Modeli İnsan Tercihlerine Göre Hizalamak
00:21:46 - RLHF (Reinforcement Learning from Human Feedback) Mantığı
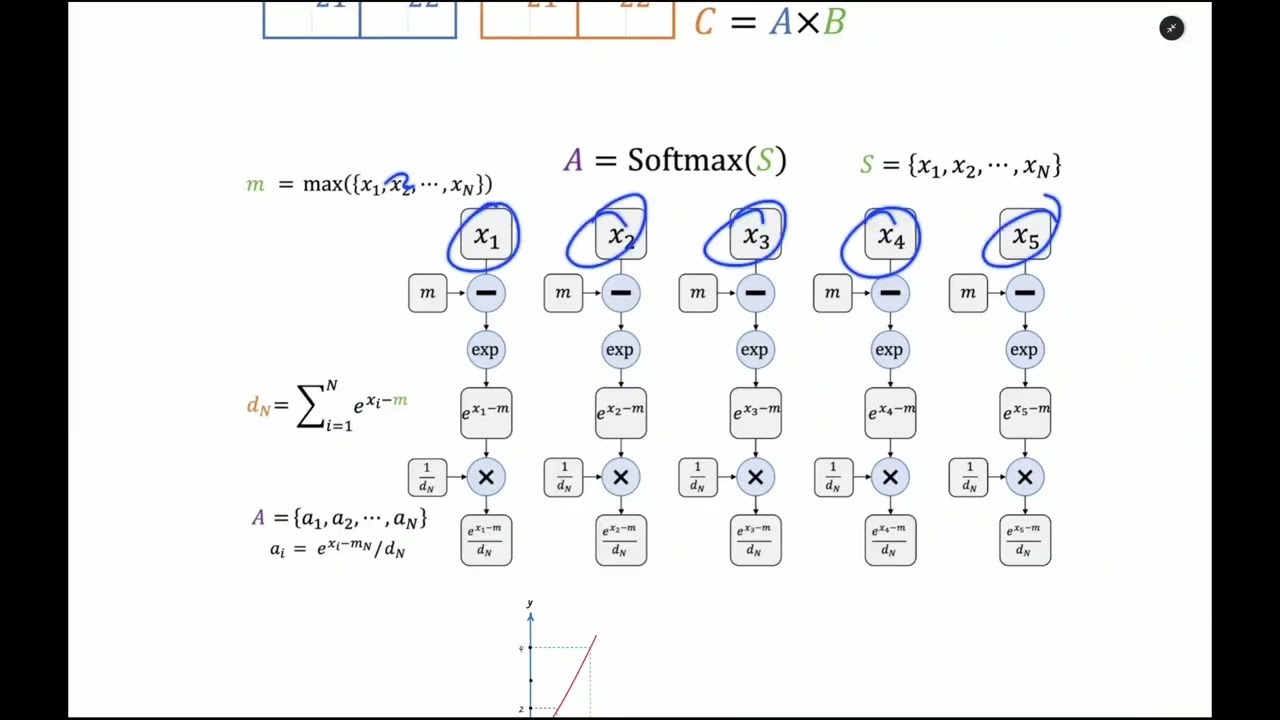
00:24:12 - Reward Model (Ödül Modeli) Nasıl Eğitilir? Bradley-Terry Formülasyonu
00:28:17 - Model Eğitimi ve İnsan Tercihlerine Göre Ağırlık Güncelleme (Policy)
00:30:02 - PPO (Proximal Policy Optimization) ve KL Divergence
00:32:00 - Advantage Hesaplaması ve Value Function Nedir?
00:34:54 - PPO Clip Yöntemi ve Güncelleme Sınırlandırması
00:37:55 - PPO'nun Dezavantajları ve DPO'ya (Direct Preference Optimization) Geçiş
00:41:22 - GRPO (Group Relative Policy Optimization): DeepSeek'in Optimizasyon Yöntemi
00:46:10 - PPO, DPO ve GRPO Karşılaştırması ve Kapanış
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: