LLM'lerde Dikkat (Attention) Optimizasyonu: PagedAttention ve FlashAttention
Автор: Sami Yusuf Turan
Загружено: 2026-02-20
Просмотров: 18
Описание:
00:00:00 - Attention Optimizasyonlarına Giriş: VRAM ve Hesaplama Sorunları
00:00:22 - PagedAttention Nedir? KV Cache ve Bellek İsrafı (Fragmentation) Problemi
00:02:57 - İşletim Sistemlerinden İlham Alan Çözüm: Paged Virtual Memory Analojisi
00:05:18 - Memory Sharing: PagedAttention ile Ortak Hafıza Kullanımı
00:06:36 - FlashAttention'a Giriş: GPU Donanım Mimarisi (HBM ve SRAM Farkı)
00:09:03 - Tiling İşlemi: Veri Taşıma Maliyetini (Memory Access) Azaltmak
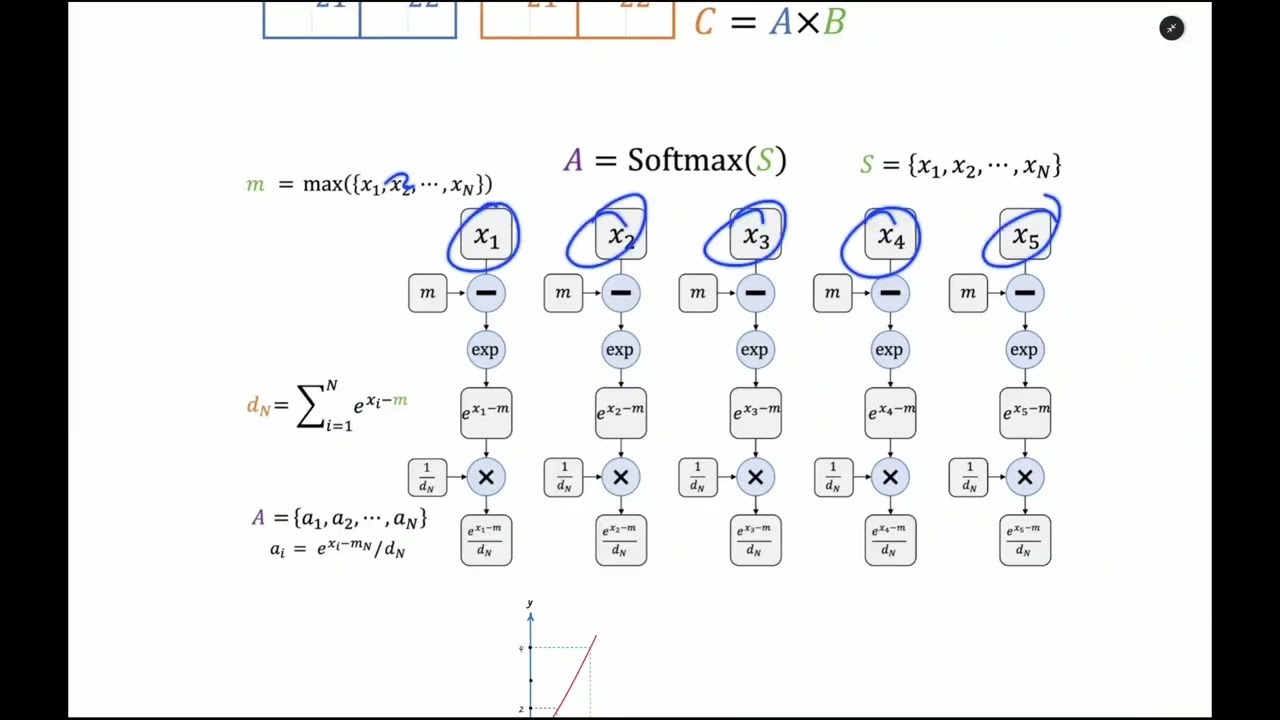
00:11:30 - Safe Softmax Nedir? Sayısal Kararlılık (Numerical Stability) Sağlamak
00:16:53 - Online Softmax: Döngü (For Loop) Sayısını Azaltmak
00:27:53 - FlashAttention'ın Temel Fikri: Git-Gel İşlemlerinden Kurtulmak
00:30:18 - PayTorch vs FlashAttention Hız Karşılaştırması
00:30:48 - İleri Seviye Optimizasyon: Forward Pass Verilerini Yeniden Hesaplamak (Recomputation)
00:32:37 - Sliding Window Attention (Longformer): O(n^2) Karmaşıklık Problemini Çözmek
00:35:13 - Dilated ve Sparse Attention: Seyreltilmiş Dikkat Mekanizması
00:36:29 - Global Sliding Window Attention ve Konu Özeti
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: