How large language models expand conceptual memory during pretraining?
Автор: Xiaol.x
Загружено: 2026-02-03
Просмотров: 61
Описание:
Representation = Trajectory? Why Modern LLMs Are Missing the Point
We are entering a new era of AI architecture. It's not just about scaling Transformers anymore—it's about "The Physics of Thought."
In this video, we visualize the lifecycle of a Concept Circuit and the proposal for a "Trillion Dollar Architecture" that fuses RWKV (Linear Attention), DeepEmb (Trajectory Memory), and Engram (Static Memory).
Most embeddings today are just a final destination—a lossy compression of a complex journey. But what if we kept the "Geodesic"—the path the model took to get there?
By combining the efficiency of Linear RNNs with the causal history of DeepEmb, we turn the internal "process" of thinking into storable "data."
Breakdown:
0:00 - The Lifecycle of a Concept Circuit
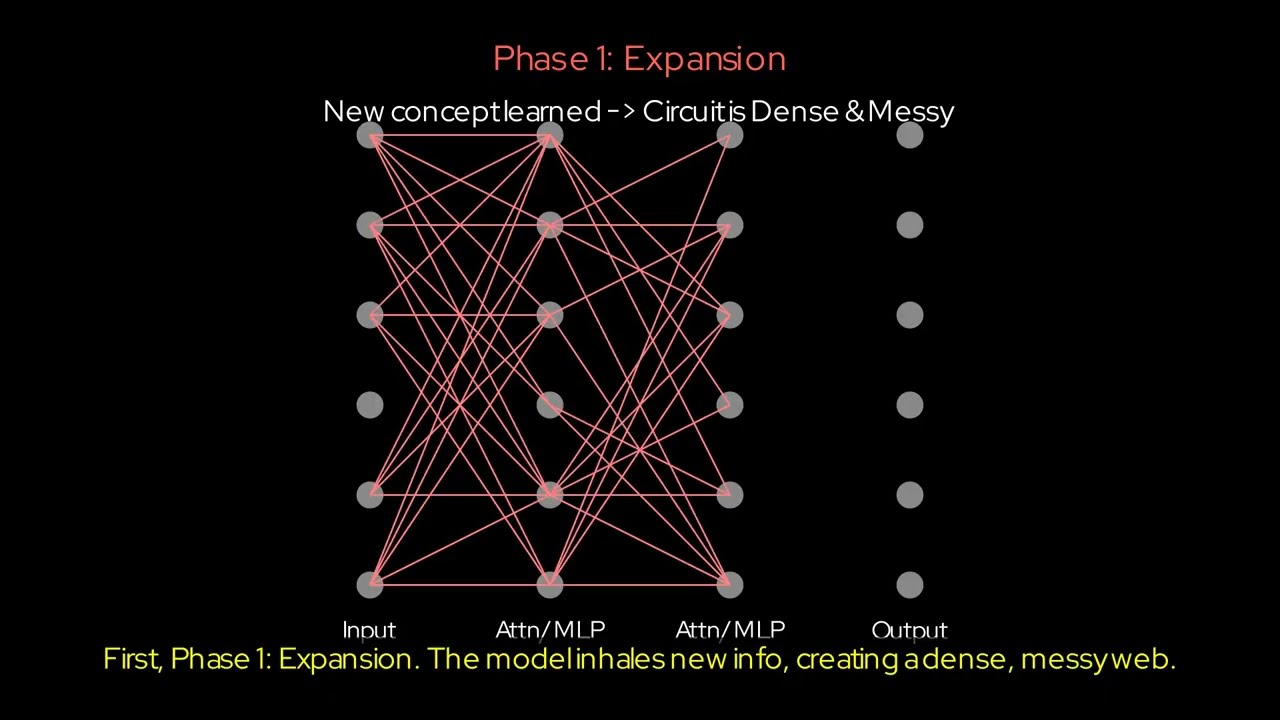
0:15 - Phase 1: Expansion (The "Big Bang" of Learning)
0:40 - Phase 2: Compression (Pruning for Modularity)
1:10 - The Trillion Dollar Architecture Intro
1:35 - Step 1: The Engram Memory Bank (Static Energy)
1:55 - Step 2: ShortConv & Momentum (The Physics)
2:15 - Step 3: RWKV State Channel Activation
2:40 - Step 4: Circuit-Aware DeepEmb
2:55 - THE ENDING: Why "Representation = Trajectory"
This visualization was generated entirely with Manim (Mathematical Animation Engine) and Python.
#AI #MachineLearning #RWKV #Transformers #DeepLearning #Manim #Visualization #ConceptCircuits #DeepEmb
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:
![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://image.4k-video.ru/id-video/Y-o545eYjXM)









![Как происходит модернизация остаточных соединений [mHC]](https://image.4k-video.ru/id-video/jYn_1PpRzxI)








