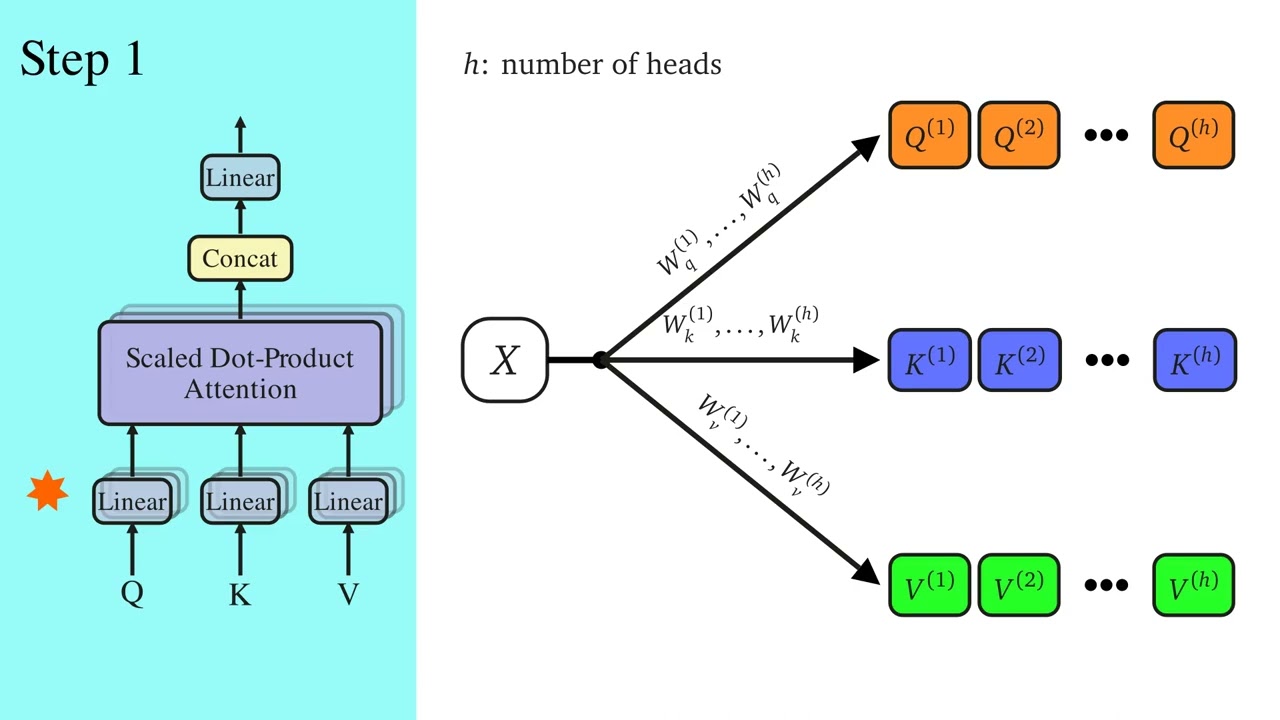
Visual Guide to Transformer Neural Networks - (Episode 3) Decoder’s Masked Attention
Автор: Hedu AI by Batool Haider
Загружено: 2021-02-02
Просмотров: 77459
Описание:
Visual Guide to Transformer Neural Networks (Series) - Step by Step Intuitive Explanation
Episode 0 - [OPTIONAL] The Neuroscience of "Attention"
• The Neuroscience of “Attention”
Episode 1 - Position Embeddings
• Visual Guide to Transformer Neural Network...
Episode 2 - Multi-Head & Self-Attention
• Visual Guide to Transformer Neural Network...
Episode 3 - Decoder’s Masked Attention
• Visual Guide to Transformer Neural Network...
This video series explains the math, as well as the intuition behind the Transformer Neural Networks that were first introduced by the “Attention is All You Need” paper.
--------------------------------------------------------------
References and Other Great Resources
--------------------------------------------------------------
Attention is All You Need
https://arxiv.org/abs/1706.03762
Jay Alammar – The Illustrated Transformer
http://jalammar.github.io/illustrated...
The A.I Hacker – Illustrated Guide to Transformers Neural Networks: A step by step explanation
http://jalammar.github.io/illustrated...
Amirhoussein Kazemnejad Blog Post - Transformer Architecture: The Positional Encoding
https://kazemnejad.com/blog/transform...
Yannic Kilcher Youtube Video – Attention is All You Need
https://www.youtube.com/watch?v=iDulh...
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:





![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)


![Что не может BERT: декодер Трансформера [Лекция]](https://imager.clipsaver.ru/ORzGEnHTSfk/max.jpg)