In-depth Review of VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Автор: Olewave
Загружено: 2023-02-03
Просмотров: 2521
Описание:
Eager to train your own #Whisper or #GPT-4o model but running out of data? We are proud to offer this unique large-scale conversational speech dataset in different languages and topics for #ASR, #TTS, #NLP, and other conversational AI R&D. It has speaker labels and high quality transcriptions. The duration of the dataset depends on the customer's needs and can extend up to 1 million hours. See the description and samples in the following post:
/ olewave-large-scaled-convesational-speech-...
send an email to [email protected] for more details.
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
https://arxiv.org/abs/2301.02111
Abstract.
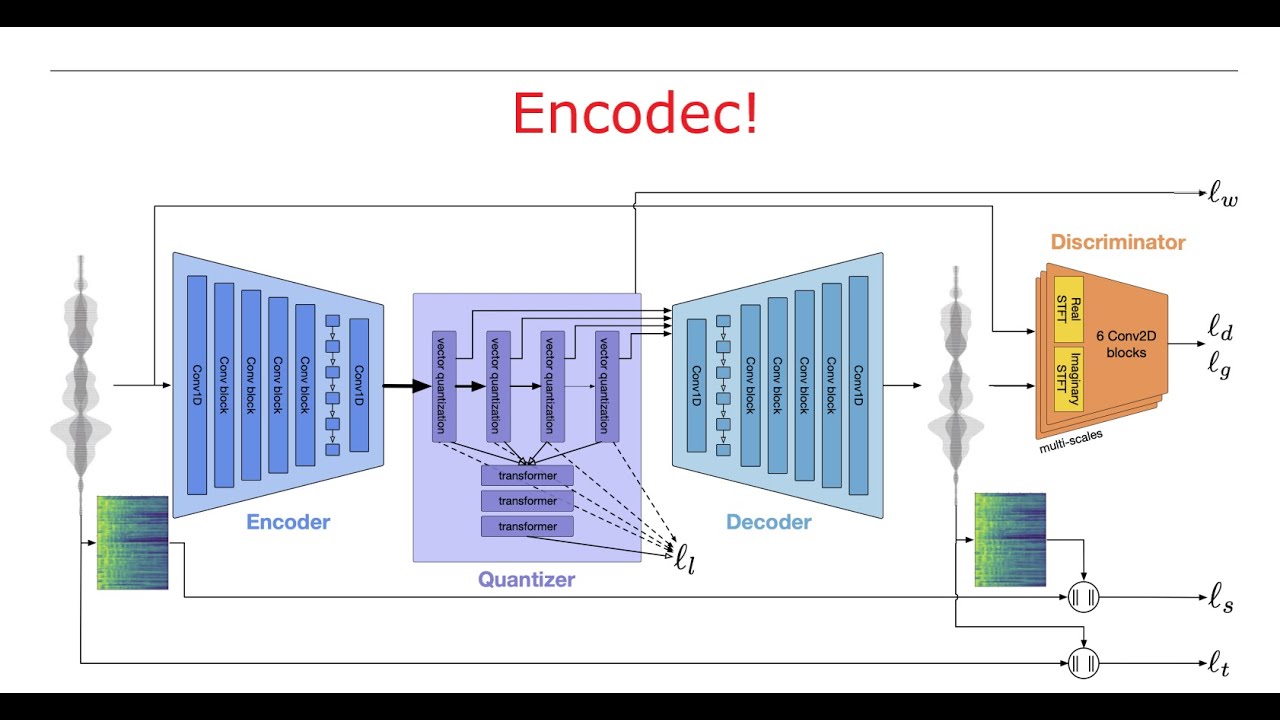
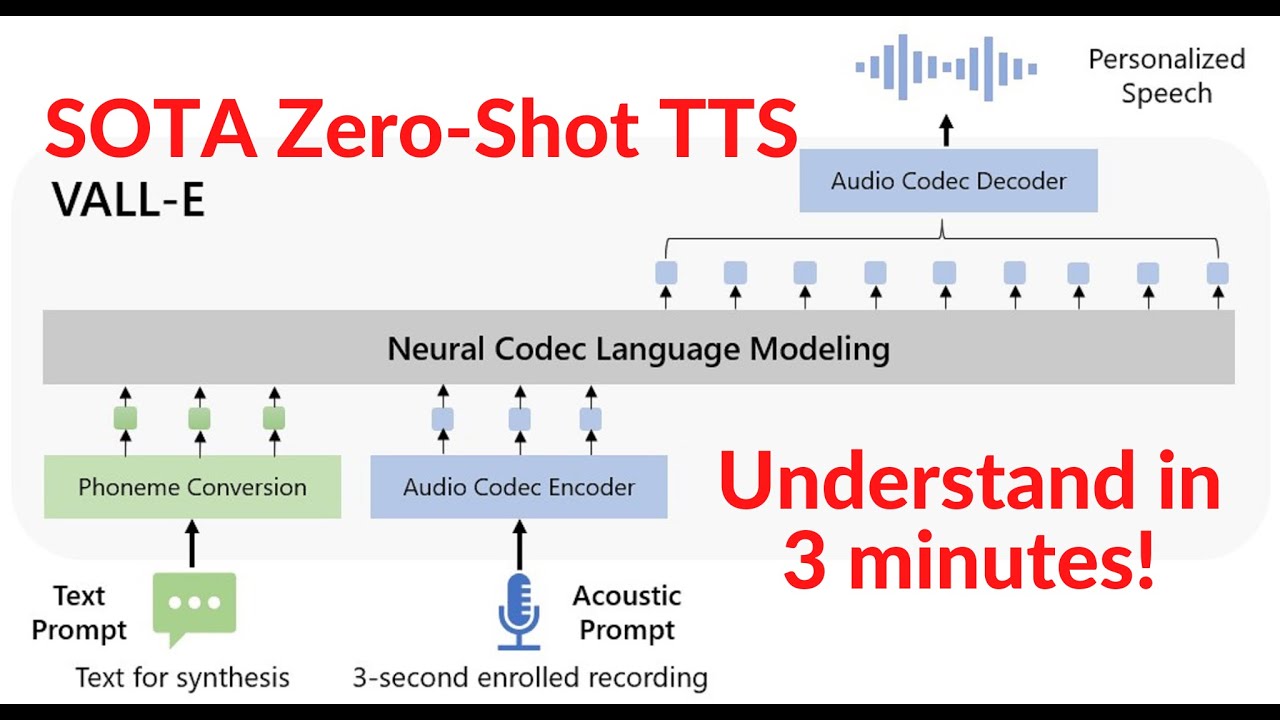
We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis.
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:











![[Olewave's Review] AudioLM: a Language Modeling Approach to Audio Generation](https://imager.clipsaver.ru/Vucewi_kPEU/max.jpg)