Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular
Автор: AI Performance Engineering
Загружено: 2025-11-17
Просмотров: 992
Описание:
Zoom link: https://us02web.zoom.us/j/82308186562
Talk #0: Introductions and Meetup Updates
by Chris Fregly and Antje Barth
Talk: Speed of Light Inference w/ NVIDIA and AMD GPUs using the Modular Platform by Abdul Dakkak @ Modular
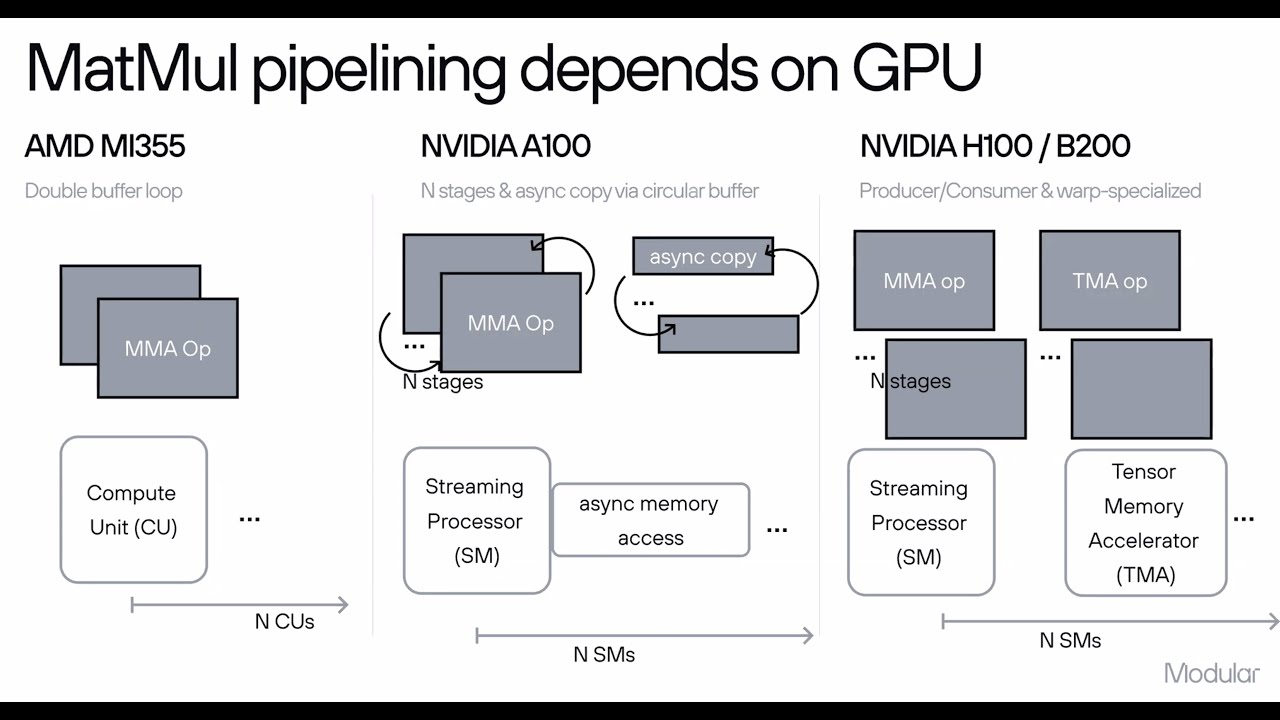
This technical presentation will demonstrate how the Modular platform can be used to scale AI workloads across various clusters. It will delve into the collaborative functionality of the Modular stack, encompassing Modular Cloud (a cluster-level solution), MAX (the framework and runtime), and Mojo (the programming language). Together, these components deliver exceptional performance and significantly reduce Total Cost of Ownership (TCO) across both NVIDIA and AMD GPU architectures.
Zoom link: https://us02web.zoom.us/j/82308186562
Related Links
Github Repo: http://github.com/cfregly/ai-performa...
O'Reilly Book: https://www.amazon.com/Systems-Perfor...
YouTube: / @aiperformanceengineering
Generative AI Free Course on DeepLearning.ai: https://bit.ly/gllm
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:









![Чистая АРХИТЕКТУРА GOLANG — ультимативный гайд на реальном проекте [за 3 часа]](https://imager.clipsaver.ru/lc3ATNxWQbI/max.jpg)









