How RAG Actually Works: The Complete Architecture Explained (AWS GenAI Ep 8)
Автор: Pratik Joshi
Загружено: 2026-02-10
Просмотров: 187
Описание:
What actually happens between your prompt and the AI's answer? ⚙️🧠
In Episode 8 of the AWS Generative AI Professional Course, we tear down the "Black Box" and walk through the complete end-to-end architecture of a RAG (Retrieval-Augmented Generation) system.
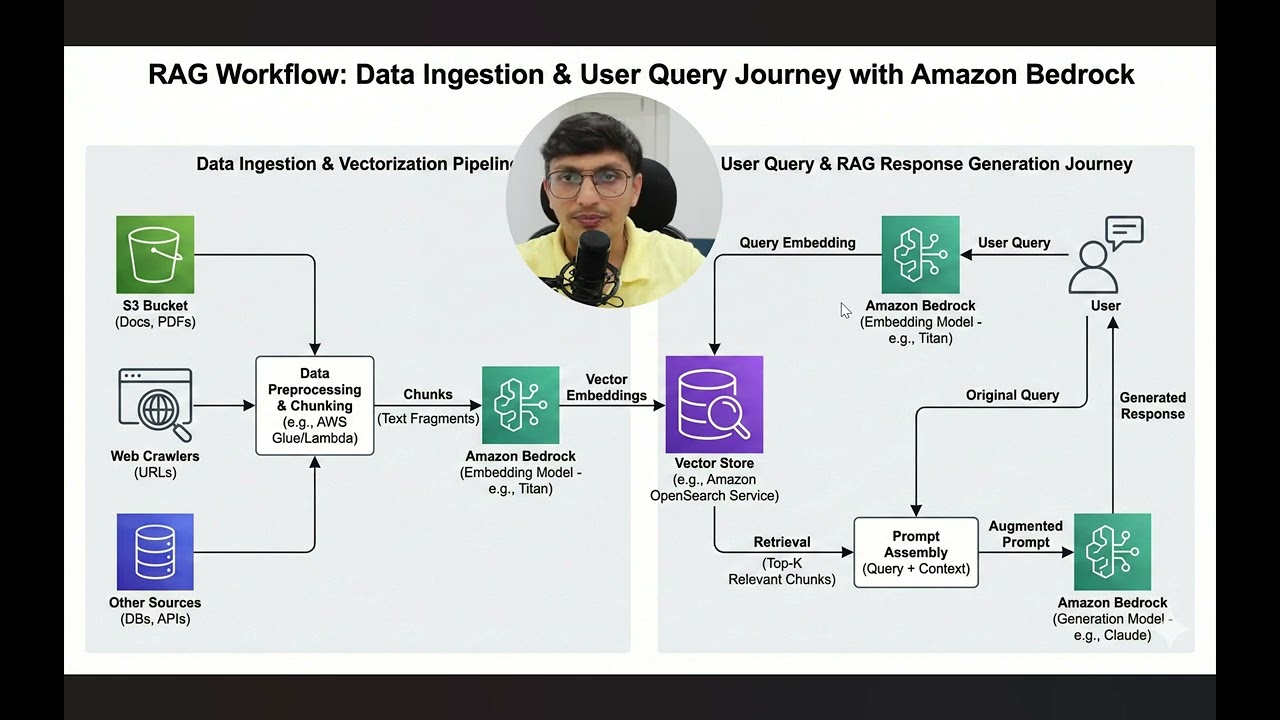
Using a production-grade architectural diagram, we break the system into its two critical lifecycles: The Ingestion Pipeline (how we prep data) and the Query Journey (how we retrieve it live).
IN THIS EPISODE, YOU WILL LEARN:
🔹 The Ingestion Pipeline: How to move data from S3/Web Crawlers to Chunking to Embeddings to Vector Store.
🔹 The Query Journey: Tracing the user's prompt through Embedding, Retrieval, and Prompt Assembly.
🔹 The "Augmented Prompt": Seeing exactly what the LLM sees before it generates an answer.
🔹 Key AWS Services: How S3, Amazon Bedrock (Titan), and OpenSearch Service fit together.
#AWS #RAGArchitecture #GenerativeAI #SystemDesign #AmazonBedrock #VectorDatabase #MachineLearning #CloudComputing #AWSCertification #LLM
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















