Видео с ютуба Visionlanguageaction

LLMs Meet Robotics: What Are Vision-Language-Action Models? (VLA Series Ep.1)

What Are Vision Language Models? How AI Sees & Understands Images

Figure Introduces Helix: Vision-Language-Action Control in Humanoid Robotics
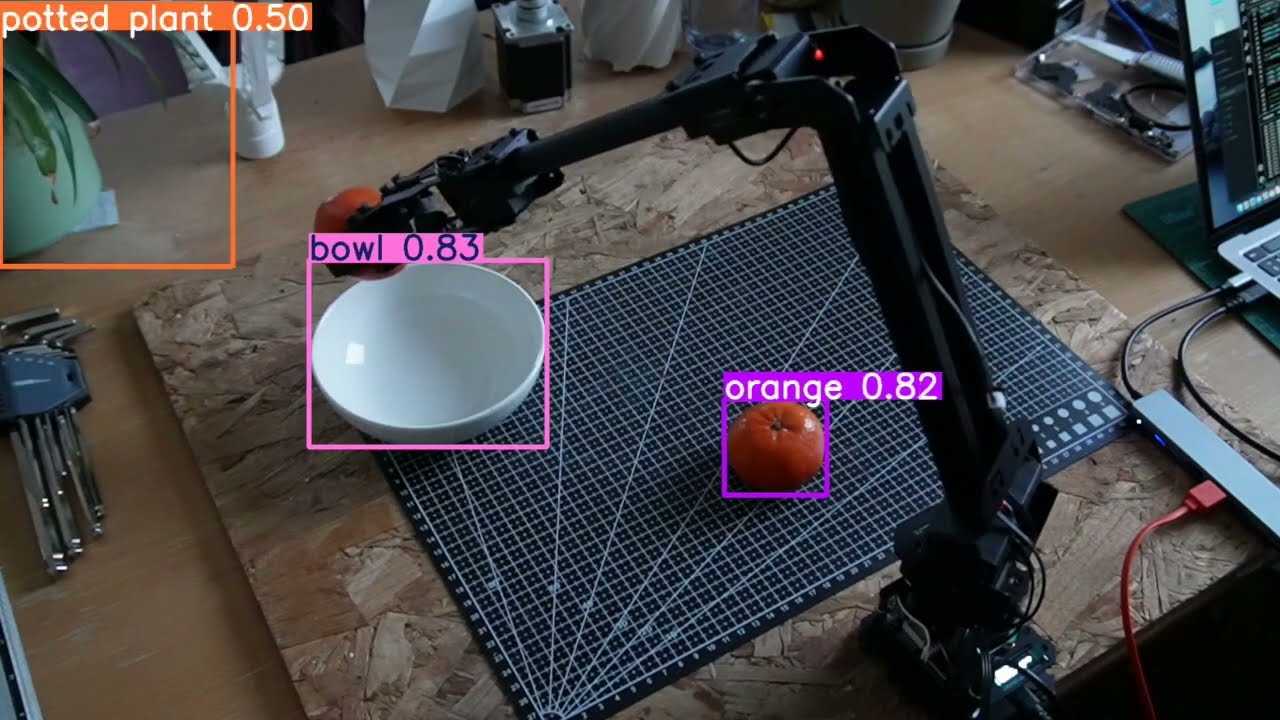
Vision-Language-Action Model v1.3 — Robotic Manipulation Test

Vision Language Action Models - OpenVLA, π0, RT-2, Gemini Robotics
![Внутри самого умного в мире роботизированного мозга [VLA]](https://imager.clipsaver.ru/2mrGMMmrVNE/max.jpg)
Внутри самого умного в мире роботизированного мозга [VLA]

Безопасность, включающая визуальное восприятие, язык и действия: угрозы, вызовы, оценки и механизмы.

Gemini Robotics: Bringing AI to the physical world

VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback

Ep#65: VLM4VLA: Revisiting Vision-Language Models in Vision-Language-Action Models

Humanoid Manipulation with Vision-Language-Action Models | ECE 398 FA25 Final | Aidan Andrews

Pi.0 Deep Dive: Flow Matching in Vision-Language-Action Models

OpenVLA: LeRobot Research Presentation #5 by Moo Jin Kim

Google's RT-2: The First Vision-Language-Action (VLA) Model Explained

ICLR2026: AutoFly: Vision-Language-Action Model for UAV Autonomous Navigation in the Wild

Humanoid VLA — Vision-Language-Action Controlled Humanoid Robot

StableVLA: Towards Robust Vision-Language-Action Models without Extra Data

RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control

XL-VLA: Cross-Hand Latent Representation for Vision-Language-Action Models