Инженерные принципы обучения модели LLM с 2 триллионами параметров
Автор: PY
Загружено: 2026-04-29
Просмотров: 23073
Описание:
DeepSeek-V3 обучил высококачественную модель MoE с 671 миллиардом параметров за 5,6 млн долларов, используя 2048 графических процессоров. Llama 3 405B использовала 16384 H100 для аналогичного качества бенчмарка. В обоих случаях использовались схожие методы обучения, но их конфигурации были совершенно разными. Аппаратное обеспечение имеет большое значение.
В этом видео мы рассмотрим все различные методы и архитектуру обучения LLM с триллионом параметров.
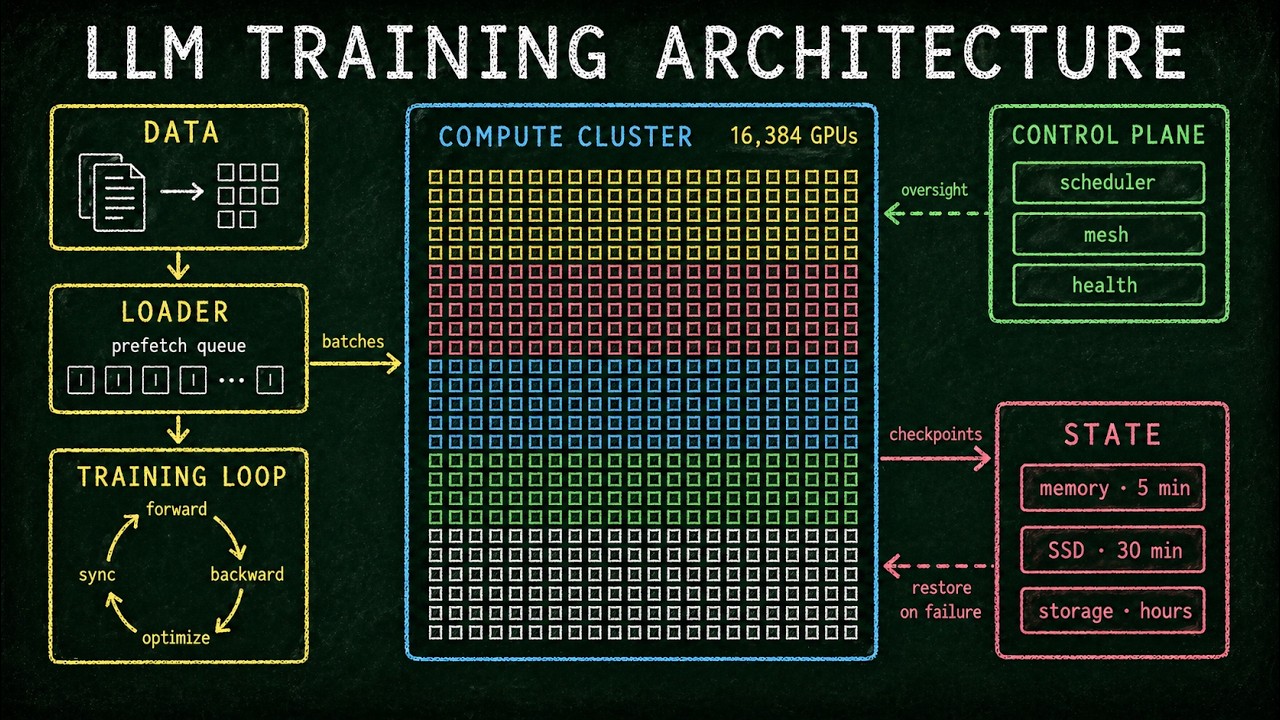
ZeRO разделяет состояние оптимизатора, градиенты и веса между графическими процессорами в три этапа. Таким образом, ни одному графическому процессору не нужно хранить всю модель целиком. FlashAttention разделяет механизм внимания на блоки SRAM и полностью избегает создания матрицы N×N, уменьшая использование памяти с O(N²) до O(N). Тензорный параллелизм разделяет умножение матриц внутри узла NVLink с 8 графическими процессорами. Если конфигурация больше, накладные расходы на связь могут стать проблематичными. Параллелизм конвейера распределяет слои по узлам, используя расписания 1F1B и обратное разделение, чтобы минимизировать «пузыри» конвейера. Метод Mixture of Experts разделяет общее количество параметров и вычисления на каждый токен, поэтому его используют все модели триллионного масштаба, включая Switch Transformer, GPT-4 и DeepSeek-V3. FP8 с пошаговым масштабированием удваивает пропускную способность H100 и поддерживает потери всего в 0,25% по сравнению с BF16 во время полного запуска DeepSeek-V3 с 14,8 триллионами токенов. Ring Attention предварительно заполняет 1 миллион токенов на Llama 3 405B за 77 секунд, используя 128 H100.
При наличии 16 384 графических процессоров кластер часто выходит из строя. Meta зафиксировала 419 неожиданных сбоев за 54 дня обучения Llama 3, в среднем один каждые три часа. Оркестратор автоматически обработал все эти проблемы, кроме трех. DeepSeek-V3 использовал другой подход на H800, избегая тензорного параллелизма, но увеличивая экспертный параллелизм до 64 и применяя пользовательское расписание DualPipe, которое перекрывает экспертную маршрутизацию с вычислениями.
GB200 NVL72 размещает 72 графических процессора в одном домене NVLink, увеличивая предел тензорного параллелизма в 9 раз. DiLoCo обучается в двух центрах обработки данных, расположенных на расстоянии 1000 км друг от друга, с эффективностью масштабирования 96%. Аппаратно-ориентированное совместное проектирование достигает качества Llama 3 при в 11 раз меньшем количестве часов работы графических процессоров. Большая часть этого стека была недоступна еще пять лет назад.
Разделы:
----------------
00:00 Обучение LLM на границе: проблема полного стека
01:00 Память LLM: 16 байт на параметр, 32 ТБ
02:30 Ring All-Reduce, LAMB и критический размер пакета
04:50 Шардинг ZeRO: состояния оптимизатора, градиенты, параметры
06:39 Контрольные точки градиента: выборочное пересчитывание активации
08:07 FlashAttention: разбиение SRAM на плитки и масштабирование Softmax
09:35 Параллелизм тензоров и последовательностей внутри узла NVLink
11:57 Параллелизм конвейера: 1F1B, чередование и обратное разделение
14:20 Ring Attention: обеспечение обучения контекста в миллион токенов
15:27 Смесь экспертов (MoE) и маршрутизация смещения DeepSeek-V3
17:08 Смешанная точность Обучение: BF16, FP8 и FP4
19:31 Llama 3 против DeepSeek-V3: две стратегии параллелизма
21:37 Правило 6ND шиншиллы: почему обучение стоит 750 миллионов долларов
22:58 419 аппаратных сбоев Llama 3 и восстановление с помощью резервного копирования
24:27 Сквозное обучение LLM: данные, сетка, плоскость управления
27:05 GB200 NVL72, DiLoCo и аппаратно-ориентированное совместное проектирование
Ссылки:
-------------------
ZeRO: Оптимизация памяти для обучения моделей с триллионом параметров (Rajbhandari et al. 2019) https://arxiv.org/abs/1910.02054
FlashAttention (Dao et al. 2022) https://arxiv.org/abs/2205.14135
Сокращение пересчета активации в больших моделях трансформеров (Korthikanti et al. 2022) https://arxiv.org/abs/2205.05198
Параллелизм конвейера с нулевым пузырьком (Qi et al. 2023) https://arxiv.org/abs/2401.10241
Кольцевое внимание с блочными трансформерами (Liu et al. 2023) https://arxiv.org/abs/2310.01889
Трансформеры с переключателями (Fedus et al. 2021) https://arxiv.org/abs/2101.03961
LAMB: обучение BERT за 76 минут (You et al. 2019) https://arxiv.org/abs/1904.00962
Обучение вычислительно-оптимальных больших языковых моделей / Chinchilla (Hoffmann et al. 2022) https://arxiv.org/abs/2203.15556
Стадо моделей Llama 3 (Grattafiori et al. 2024) https://arxiv.org/abs/2407.21783
Технический отчет DeepSeek-V3 (DeepSeek-AI 2024) https://arxiv.org/abs/2412.19437
DiLoCo: Распределенное обучение языковых моделей с низким уровнем коммуникации (Douillard et al. 2023) https://arxiv.org/abs/2311.08105
#llm #deepseek #aitraining #largelanguagemodels #глубокоеобучение #распределенноеобучение #nvidia #ai #мета #google #deepmind #openai #антропоморфный #лама
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: