Rethinking Attention with Performers (Paper Explained)
Автор: Yannic Kilcher
Загружено: 2020-10-26
Просмотров: 58617
Описание:
#ai #research #attention
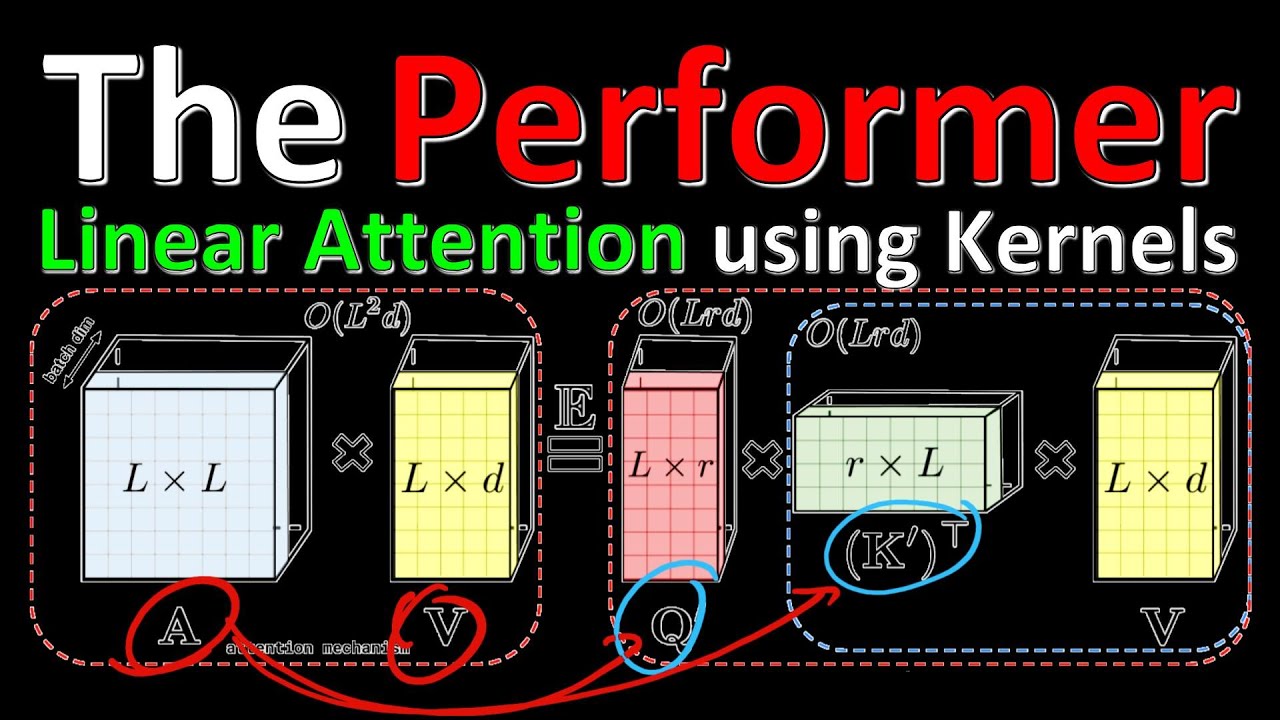
Transformers have huge memory and compute requirements because they construct an Attention matrix, which grows quadratically in the size of the input. The Performer is a model that uses random positive orthogonal features to construct an unbiased estimator to the Attention matrix and obtains an arbitrarily good approximation in linear time! The method generalizes beyond attention and opens the door to the next generation of deep learning architectures.
OUTLINE:
0:00 - Intro & Outline
6:15 - Quadratic Bottleneck in Attention Mechanisms
10:00 - Decomposing the Attention Matrix
15:30 - Approximating the Softmax Kernel
24:45 - Different Choices, Different Kernels
28:00 - Why the Naive Approach does not work!
31:30 - Better Approximation via Positive Features
36:55 - Positive Features are Infinitely Better
40:10 - Orthogonal Features are Even Better
43:25 - Experiments
49:20 - Broader Impact Statement
50:00 - Causal Attention via Prefix Sums
52:10 - Code
53:50 - Final Remarks & Conclusion
Paper: https://arxiv.org/abs/2009.14794
Code: https://github.com/google-research/go...
Blog: https://ai.googleblog.com/2020/10/ret...
Kernels on ML Street Talk: • Kernels!
My Video on Linformer: • Linformer: Self-Attention with Linear Comp...
My Video on Reformer: • Reformer: The Efficient Transformer
My Video on Attention: • Attention Is All You Need
Abstract:
We introduce Performers, Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. To approximate softmax attention-kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+), which may be of independent interest for scalable kernel methods. FAVOR+ can be also used to efficiently model kernelizable attention mechanisms beyond softmax. This representational power is crucial to accurately compare softmax with other kernels for the first time on large-scale tasks, beyond the reach of regular Transformers, and investigate optimal attention-kernels. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. We tested Performers on a rich set of tasks stretching from pixel-prediction through text models to protein sequence modeling. We demonstrate competitive results with other examined efficient sparse and dense attention methods, showcasing effectiveness of the novel attention-learning paradigm leveraged by Performers.
Authors: Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
Links:
YouTube: / yannickilcher
Twitter: / ykilcher
Discord: / discord
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: / yannic-kilcher-488534136
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: / yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:

![Что ошибочно пишут в книгах об ИИ [Двойной спуск]](https://imager.clipsaver.ru/z64a7USuGX0/max.jpg)


![[Classic] Deep Residual Learning for Image Recognition (Paper Explained)](https://imager.clipsaver.ru/GWt6Fu05voI/max.jpg)

![How DeepSeek Rewrote the Transformer [MLA]](https://imager.clipsaver.ru/0VLAoVGf_74/max.jpg)
![Цепи Маркова — математика предсказаний [Veritasium]](https://imager.clipsaver.ru/QI7oUwNrQ34/max.jpg)