5th Exercise, Optimization for Machine Learning, Sose 2023, LMU Munich
Автор: Viktor Bengs
Загружено: 2026-01-09
Просмотров: 28
Описание:
All teaching material is available at: [github](https://github.com/bengsV/OptML)
This video is the fifth exercise session for the *Optimization for Machine Learning* course at LMU Munich (Summer Semester 2023), taught by Viktor Bengs. The session focuses on theoretical proofs and practical implementations of subgradient descent and conditional gradient descent.
*1. Subgradients and Regularization [[00:17]( • 5th Exercise, Optimization for Machine Lea... )]*
The instructor begins by correcting a "bug" from a previous session regarding the subgradient of the Euclidean norm.
*Proof Recap:* He demonstrates that the unit ball is the subgradient of the norm function at zero [[01:08]( • 5th Exercise, Optimization for Machine Lea... )].
* Norm:* He briefly reviews that the subgradient of the norm is a vector where each component is the sign of the corresponding parameter [[05:24]( • 5th Exercise, Optimization for Machine Lea... )].
*Coding Implementation:* The session transitions to a Python notebook to compare *Ridge ()* and *Lasso ()* regularization in least squares problems [[24:41]( • 5th Exercise, Optimization for Machine Lea... )]. He notes that the norm is non-differentiable, requiring the subgradient descent method [[26:54]( • 5th Exercise, Optimization for Machine Lea... )].
*2. Karush-Kuhn-Tucker (KKT) Conditions [[06:46]( • 5th Exercise, Optimization for Machine Lea... )]*
A significant portion of the session is dedicated to solving constrained optimization problems using KKT conditions.
*Theoretical Framework:* He recaps the KKT requirements: stationarity (gradient of the Lagrangian is zero), primal and dual feasibility, and complementary slackness [[08:20]( • 5th Exercise, Optimization for Machine Lea... )].
*Euclidean Projection:* He provides an analytical proof for the Euclidean projection onto an affine space defined by [[10:22]( • 5th Exercise, Optimization for Machine Lea... )]. Using the Lagrangian, he derives that the projection of is given by:
[[23:00]( • 5th Exercise, Optimization for Machine Lea... )].
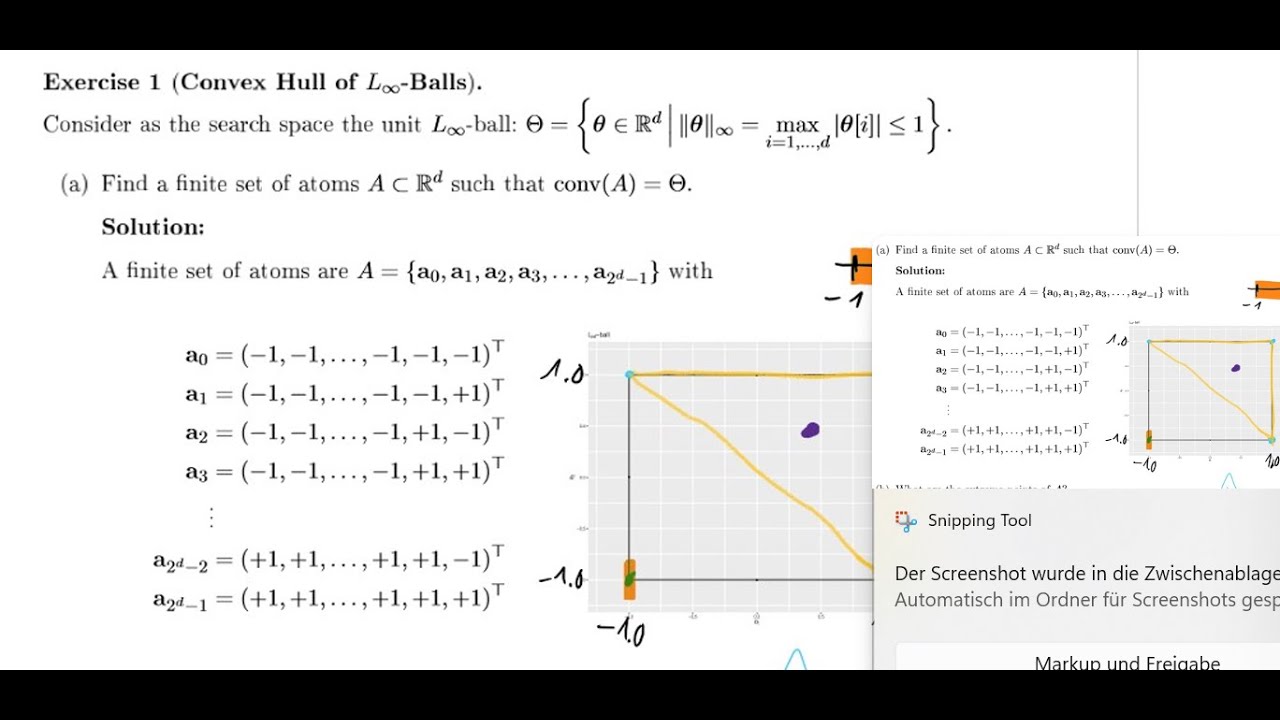
*3. Conditional Gradient (Frank-Wolfe) Descent [[40:41]( • 5th Exercise, Optimization for Machine Lea... )]*
The lecture moves to the *Conditional Gradient Descent* (also known as Frank-Wolfe), which is useful for optimization over convex hulls.
* Ball Atoms:* He proves that the "atoms" (corner points) of a d-dimensional ball are the vectors consisting of [[42:13]( • 5th Exercise, Optimization for Machine Lea... )].
*Linear Minimization Oracle:* He explains how to solve the sub-problem required for Frank-Wolfe: minimizing a linear function over the ball. The solution is simply the negative sign of the gradient vector [[01:08:02]( • 5th Exercise, Optimization for Machine Lea... )].
*Practical Coding:* The instructor implements the algorithm in Python to observe its behavior on real datasets (e.g., predicting concrete compressive strength) [[01:13:33]( • 5th Exercise, Optimization for Machine Lea... )].
*4. Observations on Step Sizes [[01:14:32]( • 5th Exercise, Optimization for Machine Lea... )]*
The session concludes with a comparison of different step-size strategies for Conditional Gradient Descent:
*Constant Step Size:* Often leads to "oscillating" behavior around the optimum [[01:16:14]( • 5th Exercise, Optimization for Machine Lea... )].
*Lipschitz and Smoothness Choices:* These strategies (e.g., using or a decaying ) provide much better stability and convergence than constant steps [[01:19:38]( • 5th Exercise, Optimization for Machine Lea... )].
The session provides both the mathematical rigor for understanding optimization constraints and the practical coding skills to apply these algorithms to machine learning tasks.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:














![Как происходит модернизация остаточных соединений [mHC]](https://image.4k-video.ru/id-video/jYn_1PpRzxI)




