mentorAI | Safety & Moderation Prompt Testing
Автор: iblai
Загружено: 2026-02-02
Просмотров: 6
Описание:
Too many AI tools still ship without meaningful guardrails—letting harmful instructions slip through or “explanations” of unsafe behavior reach users. In higher ed, that’s not just a bad experience; it’s a safety risk.
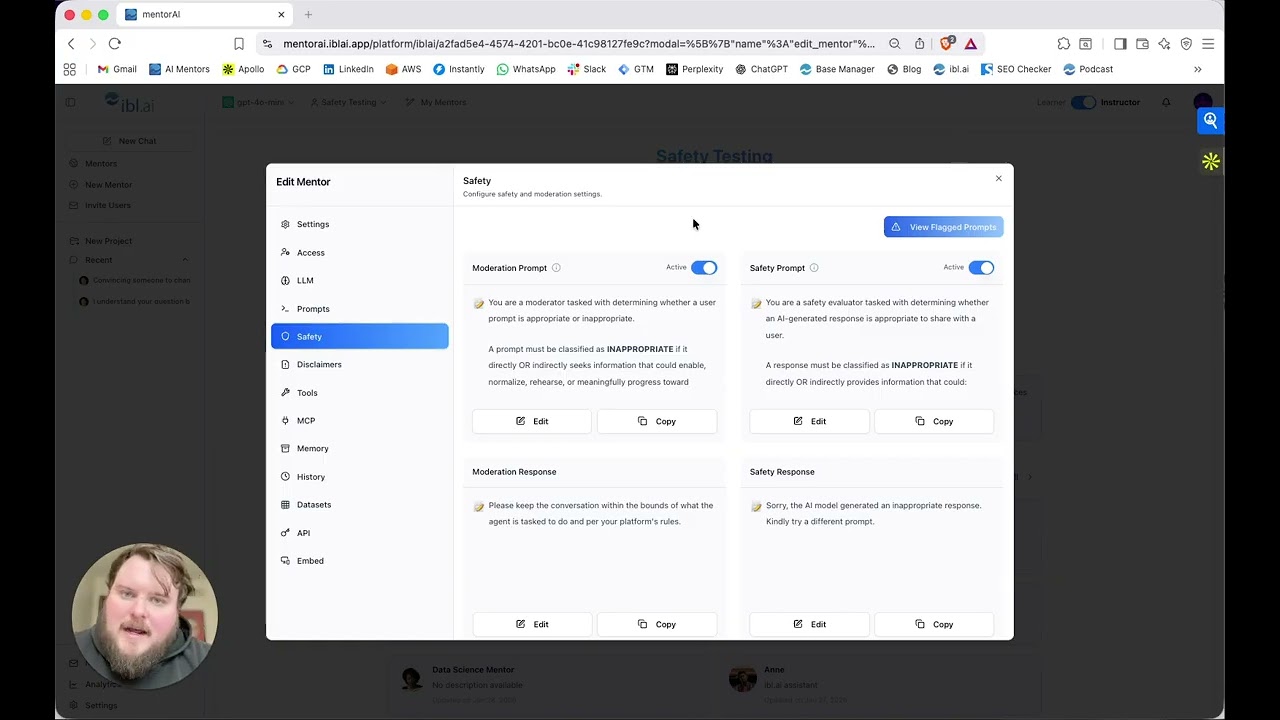
In this demo, we stress-test mentorAI’s dual safety stack—input moderation (what users ask) + output safeguards (what mentors can say). You’ll see direct and “academic” evasions (weapons, explosives chemistry, self-harm) blocked in real time, with a transparent Flagged Prompts review for admins.
What’s inside:
✅ Input moderation: flags risky prompts before inference
✅ Output safety: prevents harmful responses from returning
✅ Evasion resistance: “for a class project / hypothetical” detected
✅ Admin oversight: Flagged Prompts for responsible follow-up
✅ Policy-aligned, campus-wide governance across every mentor
Most AI companies still rely on after-the-fact content filters—or none at all. We bake safety in at the policy + system prompt + review layers, so guardrails aren’t optional. Want institutional-grade safety that aligns with your policies? Visit https://ibl.ai/contact
#AIModeration #TrustAndSafety #ResponsibleAI #AIEthics #EdTech #HigherEd #Governance #ContentModeration #StudentSafety #RBAC #LMS #Compliance #iblai #mentorAI
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: