CSCI 1109 - M50 - Clustering with k-Means; scaling effects
Автор: Atlantic AI Institute
Загружено: 2026-03-04
Просмотров: 0
Описание:
In this module, we meet our first clustering workhorse: k-means. Instead of predicting labels, we now ask a different question: if we just look at the shape of the data, what natural groups are there? You'll see how k-means treats each row as a point in feature space, pulls those points into little ``clouds'' around centroids, and why this only makes sense when your features are numeric and sensibly scaled. Using small, concrete examples (like customer behaviour and penguin measurements), we'll watch how standardization can completely change the clusters you get, and use simple diagnostics and silhouette scores to separate meaningful structure from wishful thinking.
Describe in plain language what clustering with k-means is trying to do, and how it differs from supervised prediction.
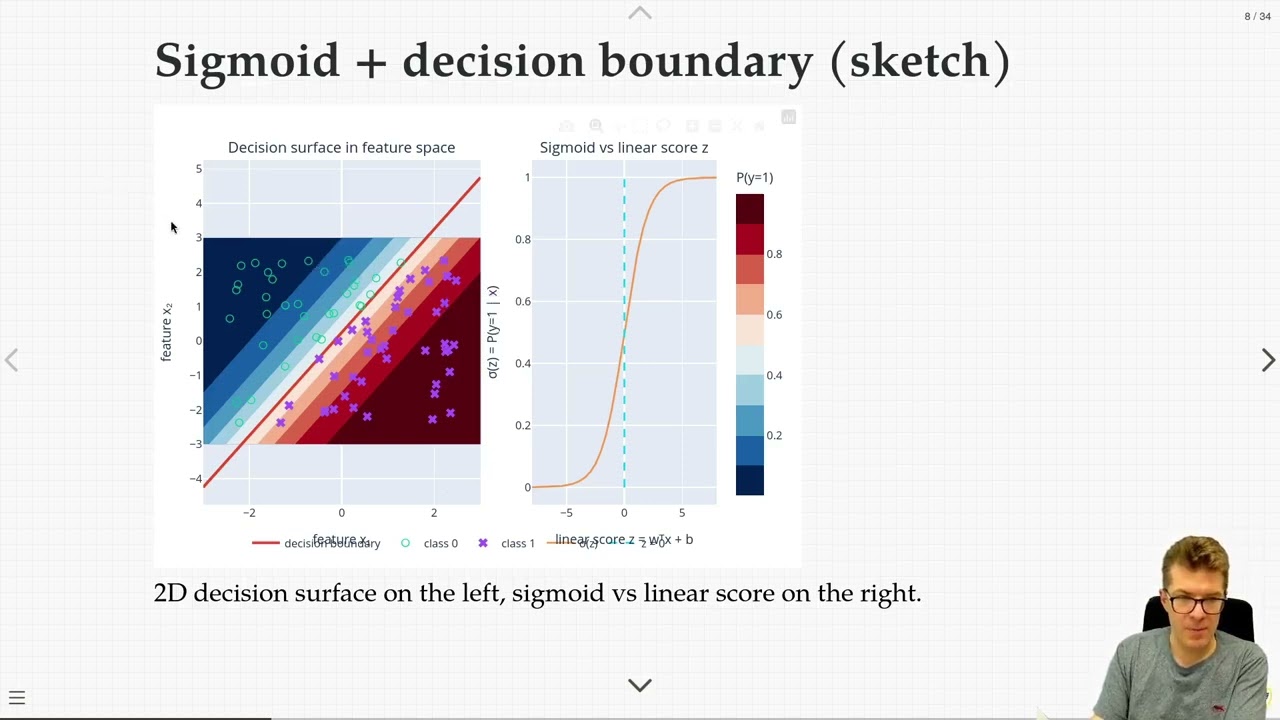
Visualize tabular data as points in 2D feature space and connect ``little clouds around centroids'' to the idea of minimizing within-cluster squared distances.
Explain why k-means assumes numeric, roughly spherical clusters and why feature scaling (e.g., standardization) can drastically change what counts as close.
Run k-means in scikit-learn with and without scaling, and interpret changes in cluster assignments, centroids, and basic summary plots.
Use simple internal metrics and visuals (elbow curves, silhouette scores, cluster profiles) to choose a reasonable number of clusters and to judge whether the patterns are likely to be useful in a real decision context.
Course module page: https://web.cs.dal.ca/~rudzicz/Teaching/CS...
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: