RAG Architecture Explained: Practical Example in 5 Minutes!
Автор: Ajay Gupta
Загружено: 2024-06-28
Просмотров: 1068
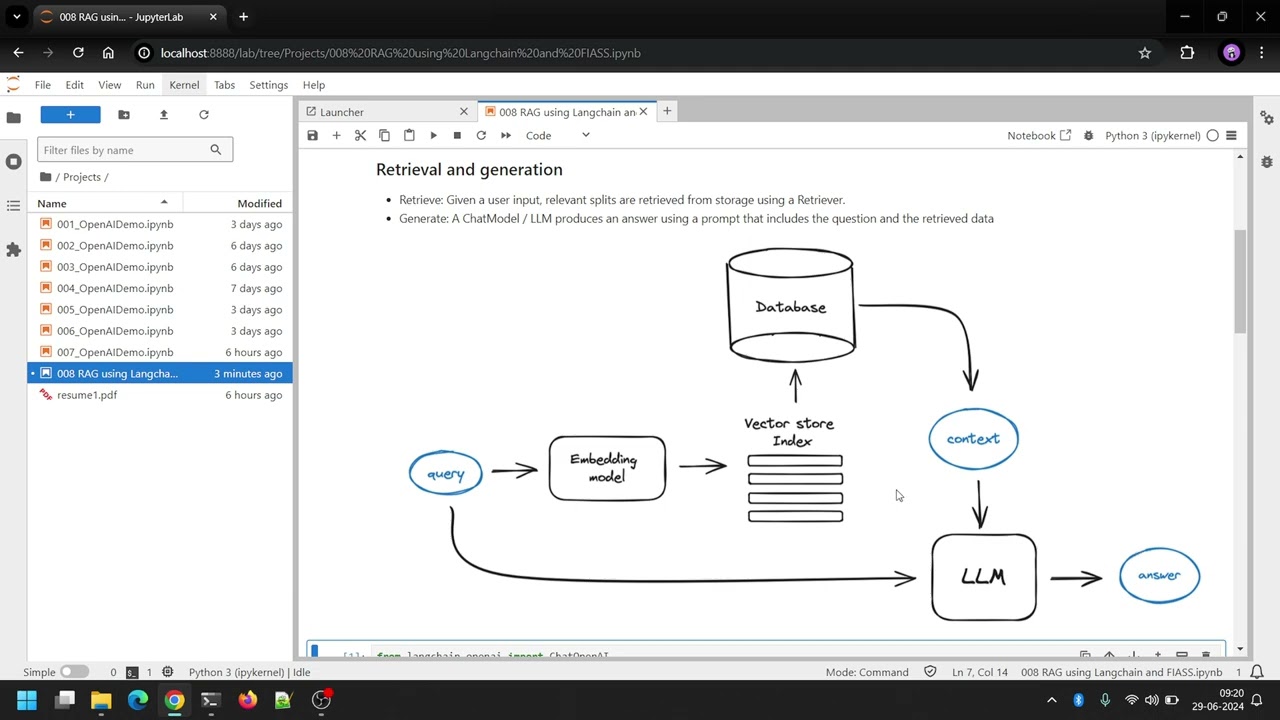
Описание: Discover the intricacies of Retrieval Augmented Generation (RAG) architecture in this concise, 5-minute tutorial. Understand the importance of RAG in enabling Large Language Models (LLMs) to reason about private or post-cutoff data, and follow along with a practical example to grasp the core concepts.What is RAG and its Importance?Understand why RAG is essential for augmenting LLMs with specific and timely information.Learn the necessity of RAG for integrating private data into AI applications.RAG Architecture Components:Indexing:Load: Utilize DocumentLoaders to efficiently load your data.Split: Implement text splitters to divide large documents into manageable chunks for better indexing and model compatibility.Store: Leverage VectorStore and Embeddings models to store and index text splits for optimized retrieval.Retrieval and Generation:Retrieve: Use a Retriever to fetch relevant text splits based on user input.Generate: Employ a ChatModel/LLM to generate responses by combining user queries with retrieved data.Practical Example:Setup and Initialization:pythonCopy codefrom langchain_openai import ChatOpenAIimport osfrom PyPDF2 import PdfReaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.vectorstores import FAISS from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv())llm = ChatOpenAI( model="gpt-4o", temperature=0, max_tokens=None, timeout=None, max_retries=2, api_key=os.environ.get("OPENAI_API_KEY"),)Document Loading and Splitting:pythonCopy codedoc_reader = PdfReader('resume1.pdf')raw_text = ''for i, page in enumerate(doc_reader.pages): text = page.extract_text() if text: raw_text += texttext_splitter = CharacterTextSplitter( separator = "\n", chunk_size = 1000, chunk_overlap = 200, length_function = len,)texts = text_splitter.split_text(raw_text)Embedding and Storing:pythonCopy codeembeddings = OpenAIEmbeddings()docsearch = FAISS.from_texts(texts, embeddings)Retrieval and Response Generation:pythonCopy codefrom langchain.chains.question_answering import load_qa_chainchain = load_qa_chain(llm, chain_type="stuff")query = "What are the core technical skills?"docs = docsearch.similarity_search(query)response = chain.invoke({"input_documents": docs, "question": query})print(response["output_text"])Conclusion:Gain a solid understanding of RAG architecture and its practical application.Optimize your AI models to effectively handle specific, real-time data.Connect with me on LinkedIn - / post your questions and suggestions in the comments section below.#genai #openai #openaichat #openaiapi #openaichatgpt #langchain #python #pythonprogramming #llm #llms #chatgpt #chatbot #rag #retrievalaugmentedgeneration
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















