Word2Vec Explained! CBOW vs Skip-gram, Negative Sampling & Hierarchical Softmax (NLP Tutorial)
Автор: Antosh Dyade
Загружено: 2026-01-23
Просмотров: 6
Описание:
Unlock the power of Word Embeddings! 🚀 In this video, we break down Word2Vec, the revolutionary NLP technique developed by researchers at Google that maps words into a high-dimensional vector space. We dive deep into how machines understand semantic relationships—like the famous example: King - Man + Woman = Queen.
Whether you are a data scientist, student, or developer, this tutorial explains the math and intuition behind efficient word representation.
In this video, you will learn:
🔹 The Two Main Architectures:
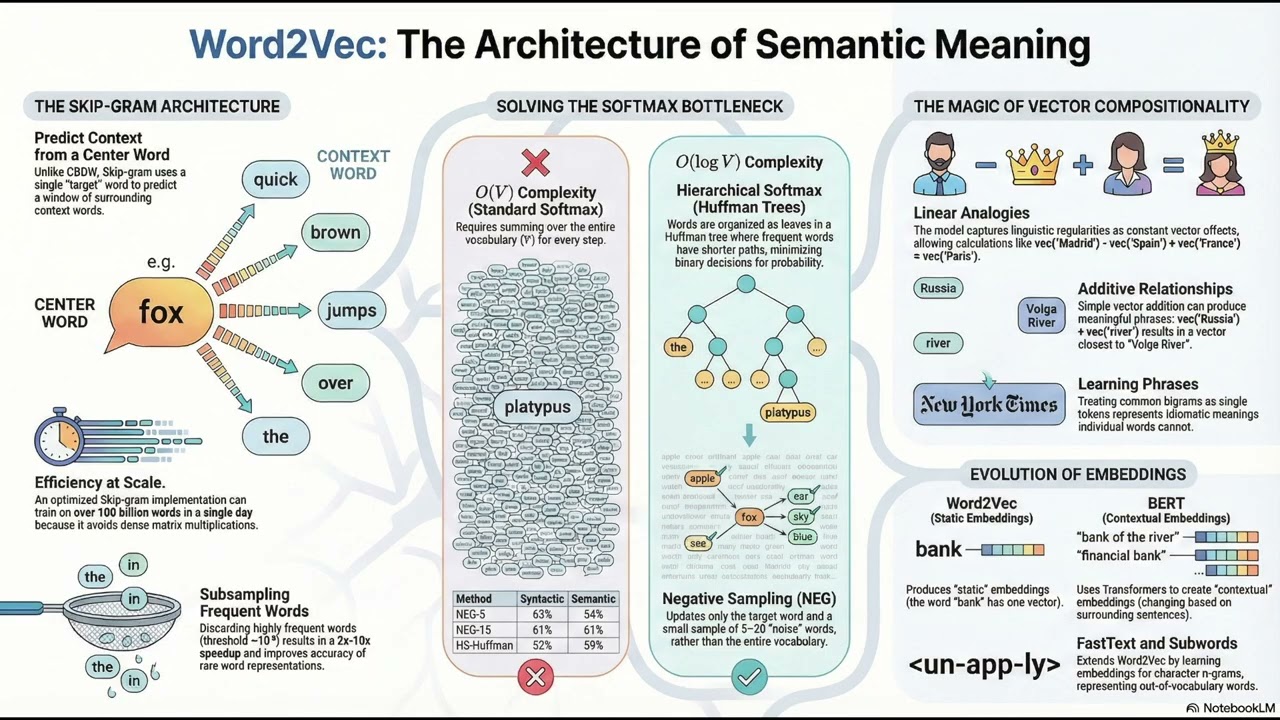
• CBOW (Continuous Bag-of-Words): Predicts a target word based on its surrounding context words. It is generally faster to train and has higher accuracy for frequent words.
• Skip-gram: Predicts surrounding context words given a single target word. This method typically performs better with smaller datasets and is superior at representing rare words.
🔹 Solving the "Softmax" Problem: Standard Softmax is computationally expensive (O(V)) because it requires summing over the entire vocabulary for every training step. We explore the two optimization techniques that make Word2Vec scalable:
1. Negative Sampling (SGNS): Transforms the problem into a binary classification task by distinguishing "real" context words from "noise" words sampled from a distribution. This allows us to update only a fraction of the weights, drastically improving training speed.
2. Hierarchical Softmax: Organizes the vocabulary into a binary Huffman tree, reducing computational complexity from linear to logarithmic (O(logV)). The probability of a word is calculated via a path from the root to the leaf node.
🔹 Word2Vec vs. The Rest:
• GloVe: Uses global matrix factorization and counts rather than local context windows.
• FastText: Improves upon Word2Vec by breaking words into character n-grams, allowing it to handle out-of-vocabulary (OOV) words and morphologically rich languages.
• BERT: Unlike the static embeddings of Word2Vec, BERT provides contextualized/dynamic embeddings where the vector changes based on the sentence.
Key Takeaways:
• Word2Vec creates dense vector representations where semantic similarity is measured by cosine distance.
• The Skip-gram model with Negative Sampling is often the top performer for semantic tasks on large datasets.
• Subsampling frequent words (like "the" or "and") accelerates training and improves the accuracy of rare word vectors.
Timestamps: 0:00 - Introduction to Word Embeddings 1:15 - How Word2Vec Works (The Intuition) 2:45 - Architecture 1: Continuous Bag-of-Words (CBOW) 4:20 - Architecture 2: Continuous Skip-gram 6:10 - The Computational Bottleneck (The Softmax Problem) 7:30 - Optimization: Hierarchical Softmax & Huffman Trees 9:45 - Optimization: Negative Sampling Explained 11:50 - Word2Vec vs. GloVe vs. FastText 13:10 - Implementation with Gensim
📚 References & Further Reading:
• "Efficient Estimation of Word Representations in Vector Space" (Mikolov et al., 2013).
• "Distributed Representations of Words and Phrases and their Compositionality" (Mikolov et al., 2013).
• Gensim Documentation for Word2Vec.
#NLP #MachineLearning #Word2Vec #DeepLearning #DataScience #Python #Gensim #ArtificialIntelligence #SkipGram #CBOW
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















