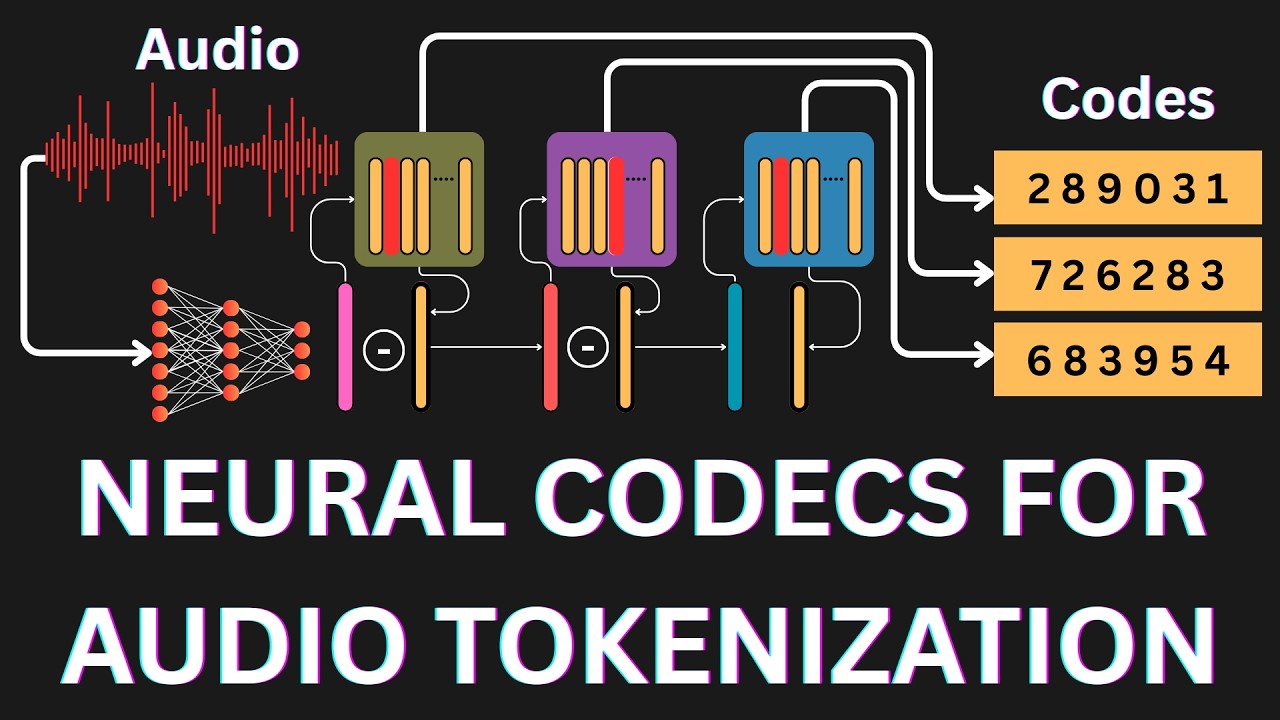
Можно ли токенизировать речь так же, как текст? Краткий обзор нейронных кодеков.
Автор: Priyam Mazumdar
Загружено: 2026-02-20
Просмотров: 443
Описание:
Сегодня мы рассмотрим общие идеи, лежащие в основе современных нейронных кодеков. Они во многом заимствуют идеи из предыдущих работ по кодекам, просто переосмысленных для глубокого обучения. Вместо разработанных вручную блоков обработки сигналов, таких как фильтровые банки, психоакустические модели и тщательно спроектированные квантизаторы, мы теперь обучаемся этим компонентам непосредственно из данных. Но основные идеи на удивление те же!
Цель этого видео — подготовить почву для будущего видео, посвященного воспроизведению модели EnCodec!
Временные метки:
00:00:00 — Введение
00:00:20 — Что такое кодек?
00:02:15 — Битрейты
00:02:35 — Что такое MP3?
00:02:55 - Слуховая маскировка
00:05:20 - Психоакустика
00:07:35 - Линейное предиктивное кодирование (LPC)
00:09:00 - Высокая автокорреляция!
00:10:00 - Квантование
00:11:13 - Глубина битов
00:12:30 - Остаточное квантование и компромисс между битами и точностью
00:15:40 - Остаточное векторное квантование
00:20:50 - Резюме
00:23:50 - Переход к нейронным кодекам
00:24:20 - Модель SoundStream
00:27:50 - Модель EnCodec
00:28:45 - Балансировщик потерь
00:31:20 - Заметка об арифметическом кодировании
00:33:15 - Модель SpeechTokenizer
00:35:00 - Обучение LLM-моделей речи на кодеках
00:36:45 - Модель VALLE
00:38:55 - Что дальше?
Социальные сети!
X / data_adventurer
Instagram / nixielights
Linkedin / priyammaz
Discord / discord
🚀 Github: https://github.com/priyammaz
🌐 Вебсайт: https://www.priyammazumdar.com/
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: