Coding a Speech-to-Text Model from Scratch in PyTorch (Transformer + RVQ + CTC)
Автор: Mayank Pratap Singh
Загружено: 2026-03-18
Просмотров: 6
Описание:
I built a Speech-to-Text model from scratch using PyTorch and trained it on an A100 GPU. No APIs, no pre-trained models. Everything coded from the ground up.
Blog post:
[Speech to text]
https://blogs.mayankpratapsingh.in/ch...
[Transformers]
https://blogs.mayankpratapsingh.in/ch...
Connect with me
Linkedin
/ mayankpratapsingh022
X
https://x.com/Mayank_022
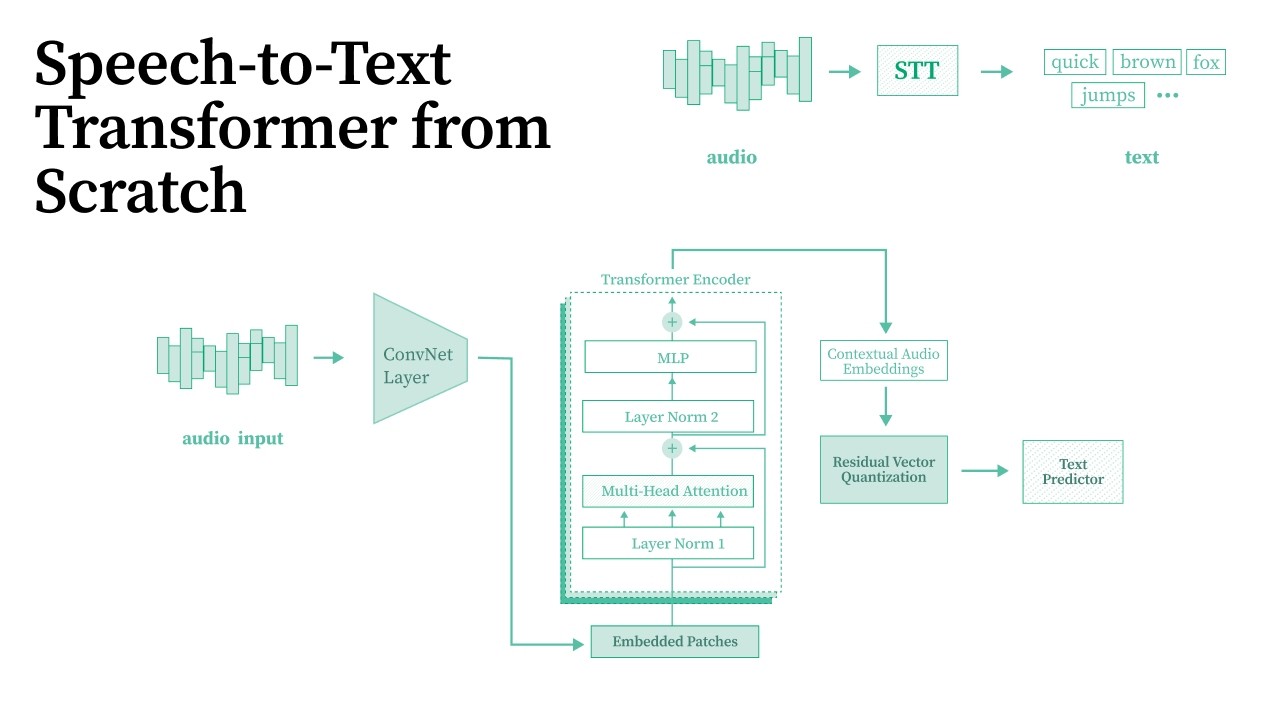
In this video I walk through the full build: how audio works digitally, why raw audio breaks self-attention, how convolutional downsampling fixes that, the Transformer encoder, Residual Vector Quantization, CTC loss, and the training loop. I also show what went wrong during training and how I debugged it.
Trained on the LJ Speech dataset. First attempt on 13,100 clips gave garbage output after 3 hours. Reduced to 200 clips, switched from BPE to character-level tokenizer, and got actual words after 2 hours.
This is a learning project, not a production model. The goal was to understand every piece of the pipeline from raw waveform to text output.
Links:
Blog post: https://blogs.mayankpratapsingh.in/ch...
GitHub repo: https://github.com/Mayankpratapsingh0...
LJ Speech dataset: https://keithito.com/LJ-Speech-Dataset/
RunPod (for GPU): https://www.runpod.io/
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















