tinyML EMEA - Baptiste Pouthier: Audio-Visual Active Speaker Detection on Embedded Devices
Автор: EDGE AI FOUNDATION
Загружено: 2023-07-13
Просмотров: 725
Описание:
Audio-Visual Active Speaker Detection on Embedded Devices
Baptiste POUTHIER
PhD Student
NXP Semiconductors
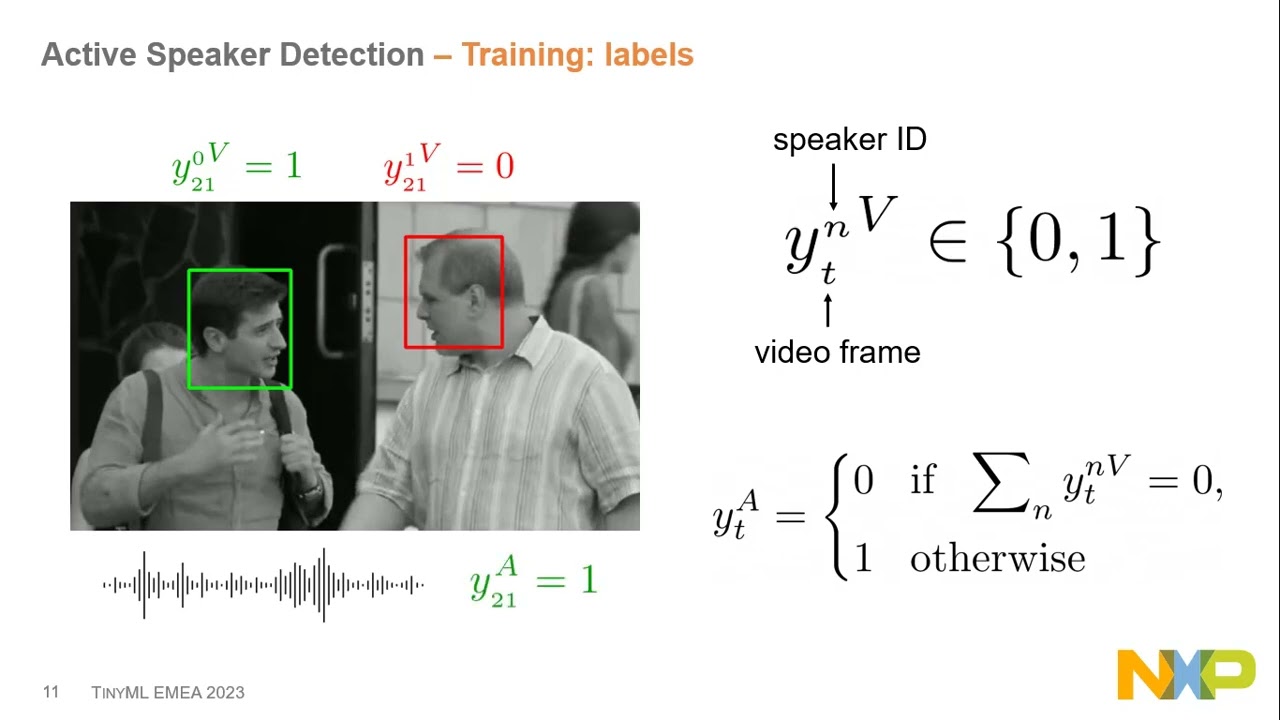
Active Speaker Detection (ASD) is the task of identifying active speakers in a video by analyzing both visual and audio features. It is a key component in human-robot interactions, for speech enhancement, and for video re-targeting in video-conferencing systems. Over the last decade, advances in machine learning have paved the way for highly reliable ASD methods. However, since both the visual and audio signals must be
processed and analyzed, these methods are extremely computationally demanding and therefore impractical for micro-controllers. For instance, most ASD models have tens of millions of parameters. Moreover, in standard use-cases like video conferencing, the model needs to run in real-time (at least 25 video frames per second) while tracking and processing multiple potential talkers. To meet the challenge, we have developed
a set of state-of-the-art ASD models with a drastic cut of the computational costs. The originality of our approach is to leverage a multi-objective optimization and a novel modality fusion scheme. In particular, we focused on building two models featuring additional architectural and optimization changes to fit two hardware configurations:
– A model that runs on high-end NXP MPU featured with quad Arm Cortex-A53 processor and with a Neural Processing Unit (NPU)
– A tiny model that runs on the dual core i.MX RT1170 MCU with Arm Cortex-M7 core at 1GHz and Arm Cortex-M4 at 400 MHz
The models are end-to-end deep learning architectures following the same block diagram The network is based on a two-branch architecture with each branch processing either the audio or the visual signal. The audio and visual embeddings are finally combined within the “fusion” block that outputs the probability of an individual speaking. This information is used by downstream algorithms, such as speech enhancement and video re-targeting, which are beyond the scope of our presentation.
All the network components are designed for hardware requirements: the fusion block, convolutional layers and temporal sequence modeling are indeed modified to optimize the model performance. The input signals are also processed accordingly: the resolution of the data and the temporal contexts used by the network are adapted to the different hardware capabilities. Our presentation is about the whole optimization and porting process, from the model design changes to the quantization and the integration on NXP devices. For each model, we focus the performance analysis on the trade-off between the computational burden and the system accuracy.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















