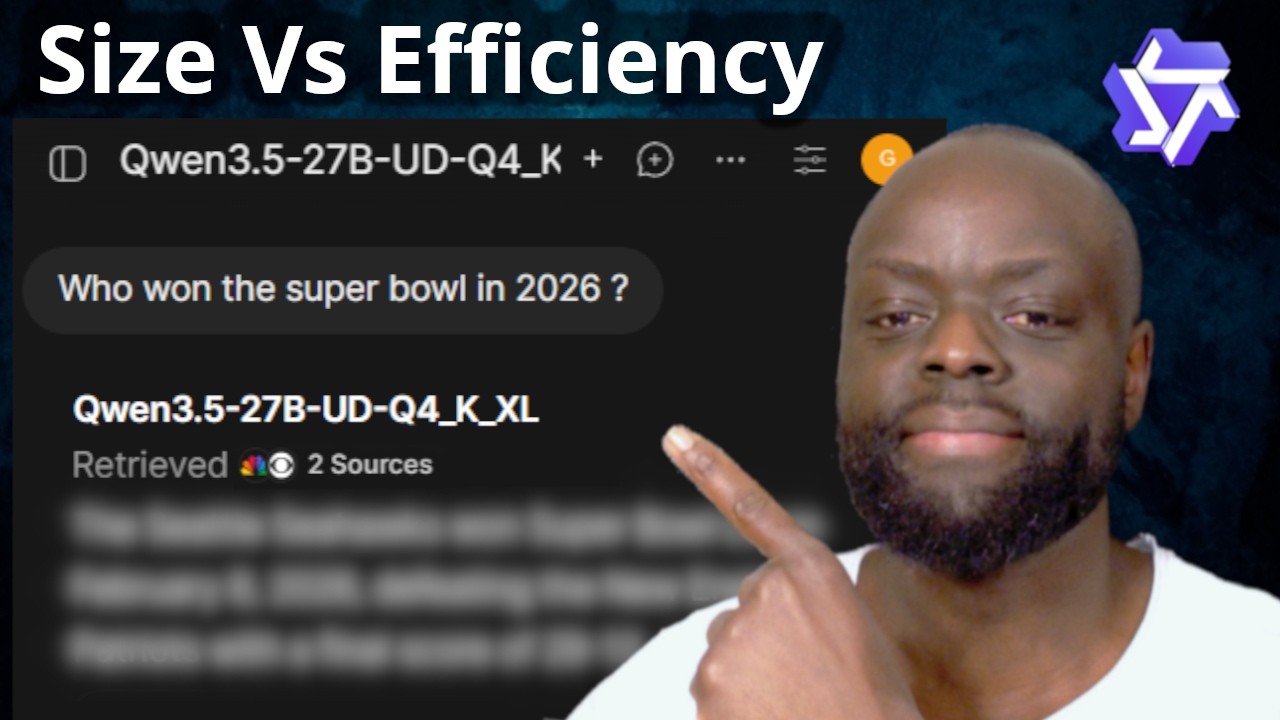
Как запустить более крупный локальный ИИ с небольшим объемом оперативной памяти | Объяснение конт...
Автор: xCreate
Загружено: 2026-03-14
Просмотров: 2904
Описание:
Вы когда-нибудь хотели запустить большой LLM, но постоянно сталкивались с нехваткой памяти? В этом видео мы рассмотрим контекстную точность, чтобы увидеть, сколько оперативной памяти мы сэкономим, и какой ценой.
Приложение Inferencer: https://inferencer.com
КУПИТЬ СЕЙЧАС
Mac Studio: https://vtudio.com/a/?a=mac+studio
MacBook Pro: https://vtudio.com/a/?a=macbook+pro
Монитор LG C2 42": https://vtudio.com/a/?a=lg+c2+42
Рекомендуемый NAS-накопитель: https://vtudio.com/a/?a=qnap+tvs-872xt
СОПУТСТВУЮЩИЕ ВИДЕО
Потоковая передача модели: • How to Run LARGE AI Models Locally with Lo...
S26 против ИИ iPhone: • Galaxy S26 Ultra vs iPhone 17 Pro - Local ...
Кластер ИИ Kimi K2.5: • Kimi K2.5 on a LOCAL AI Cluster vs ChatGPT...
ОСОБАЯ БЛАГОДАРНОСТЬ
Спасибо за вашу поддержку, и если у вас есть какие-либо предложения или вы хотите помочь нам создавать больше видео, пожалуйста, свяжитесь с нами. касание.
Ссылки на товары часто содержат партнерский код отслеживания, который позволяет нам получать комиссионные с покупок, совершенных вами через эти ссылки.
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: