Day 44: Evaluating Agentic RAG Reliability
Автор: Systemdrllp5
Загружено: 2026-02-24
Просмотров: 1
Описание:
What we build in this lesson:
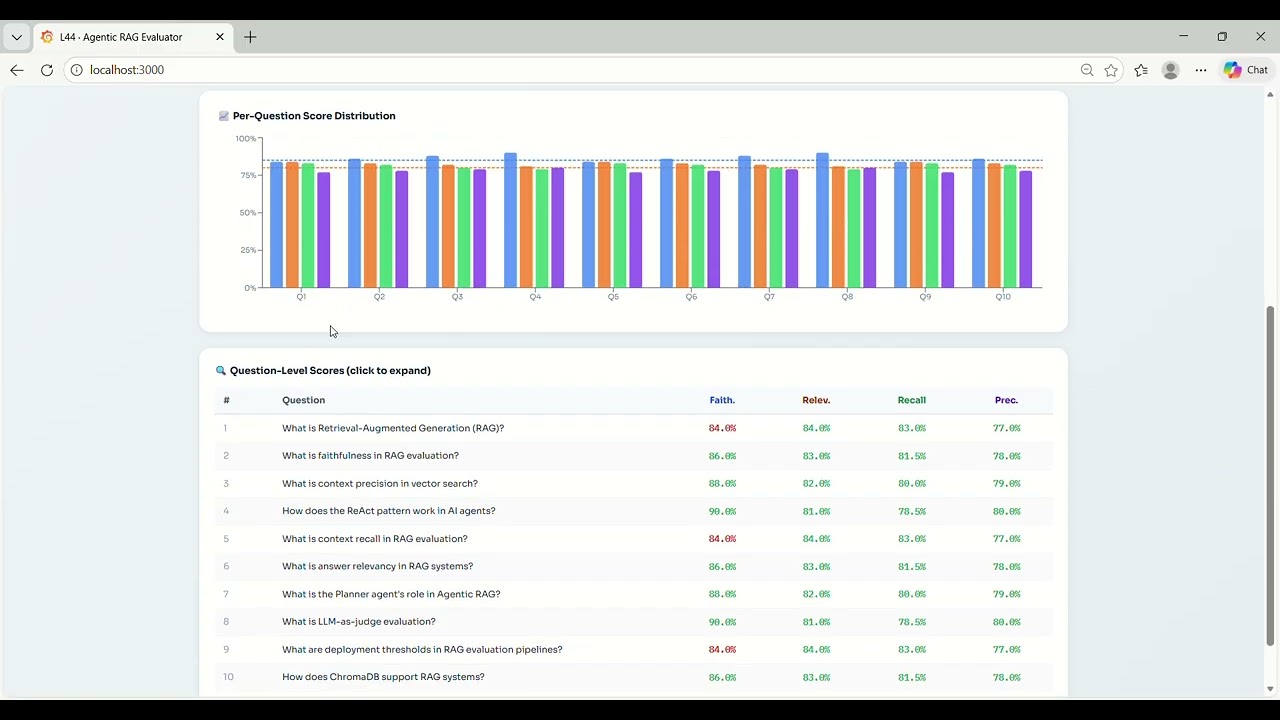
A Ragas-powered evaluation pipeline wired to Gemini as the LLM judge, measuring faithfulness, answer relevancy, context recall, and context precision
A TestDataset Generator that auto-synthesizes evaluation questions from your existing corpus — no manual labeling required
A MetricsEngine implementing both automated Ragas scoring and a custom Gemini-judge path for metrics Ragas can't cover
A live evaluation dashboard (React + Recharts) visualizing per-metric scores, per-question breakdowns, and regression trends across evaluation runs
A benchmark harness that gates pipeline changes — if faithfulness drops below threshold, deployment is blocked
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: