Backfill Streaming Data Pipelines in Kappa Architecture
Автор: Databricks
Загружено: 2022-07-19
Просмотров: 7675
Описание:
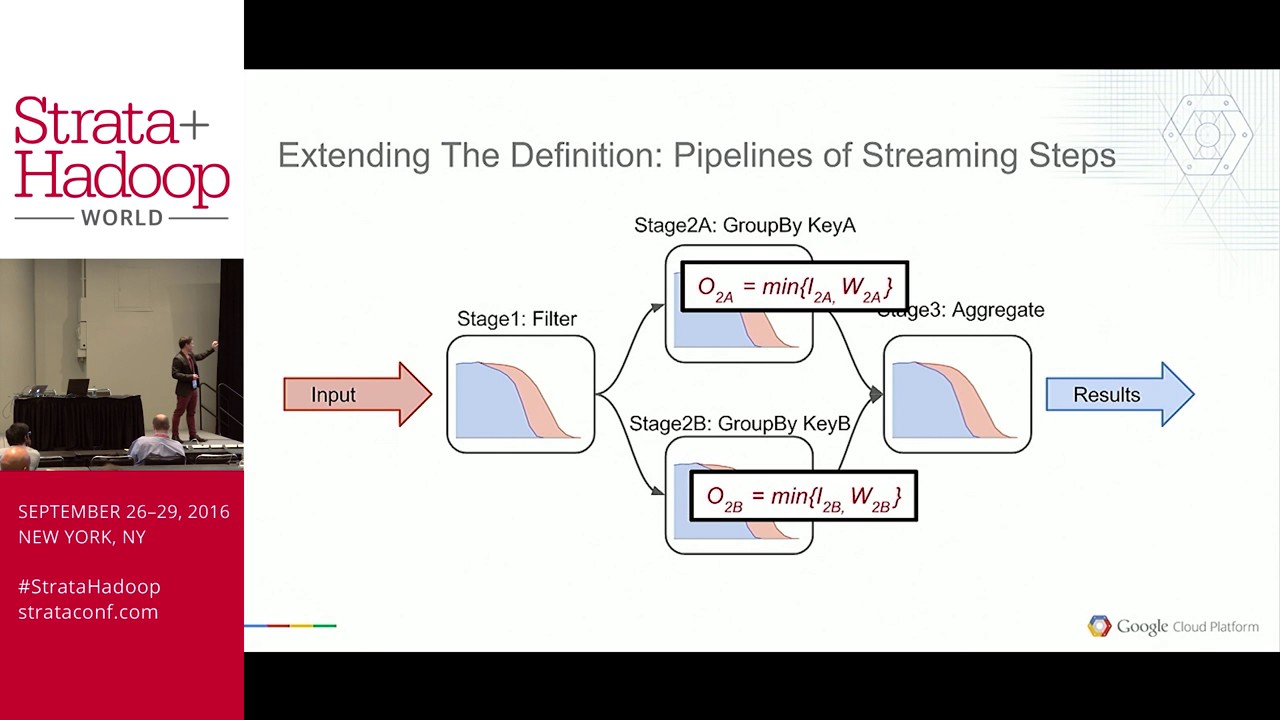
Streaming data pipelines can fail due to various reasons. Since the source data, such as Kafka topics, often have limited retention, prolonged job failures can lead to data loss. Thus, streaming jobs need to be backfillable at all times to prevent data loss in case of failures.
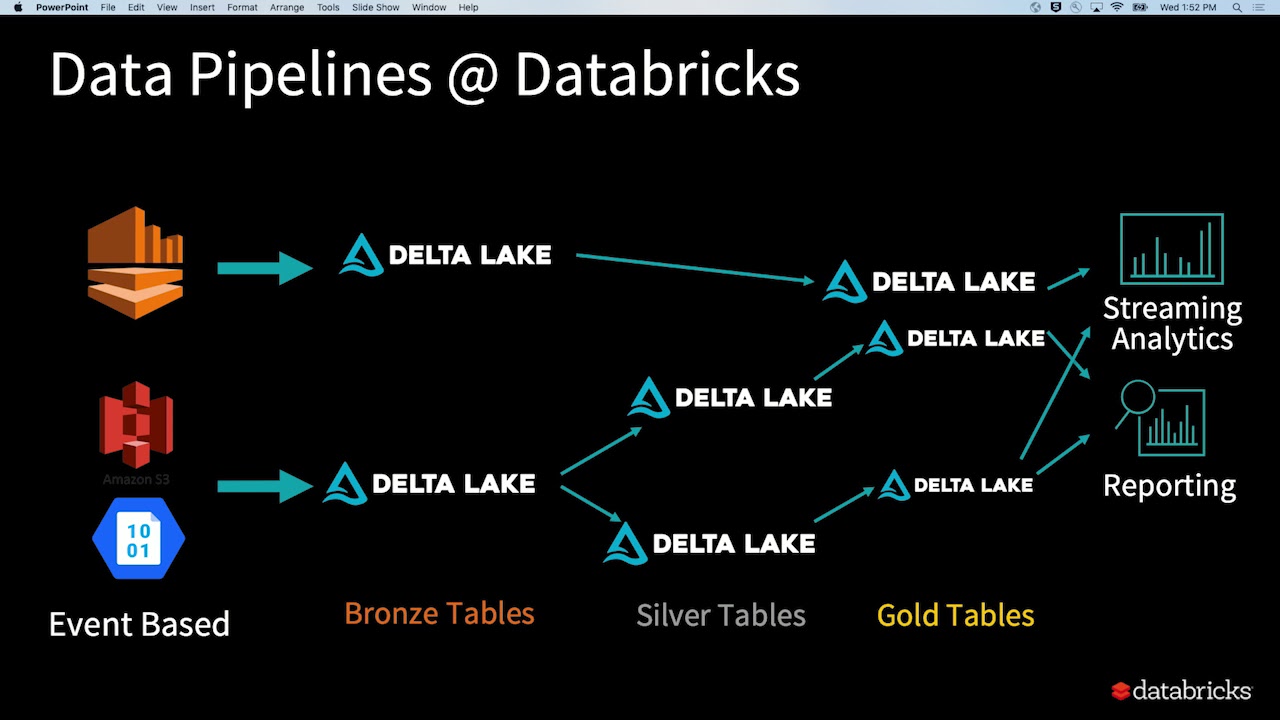
One solution is to increase the source's retention so that backfilling is simply replaying source streams, but extending Kafka retention is very costly for Netflix's data sizes. Another solution is to utilize source data stored in DWH, commonly known as the Lambda architecture. However, this method introduces significant code duplication, as it requires engineers to maintain a separate equivalent batch job.
At Netflix, we have created the Iceberg Source Connector to provide backfilling capabilities to Flink streaming applications. It allows Flink to stream data stored in Apache Iceberg while mirroring Kafka's ordering semantics, enabling us to backfill large-scale stateful Flink pipelines at low retention cost.
Connect with us:
Website: https://databricks.com
Facebook: / databricksinc
Twitter: / databricks
LinkedIn: / data. .
Instagram: / databricksinc
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: