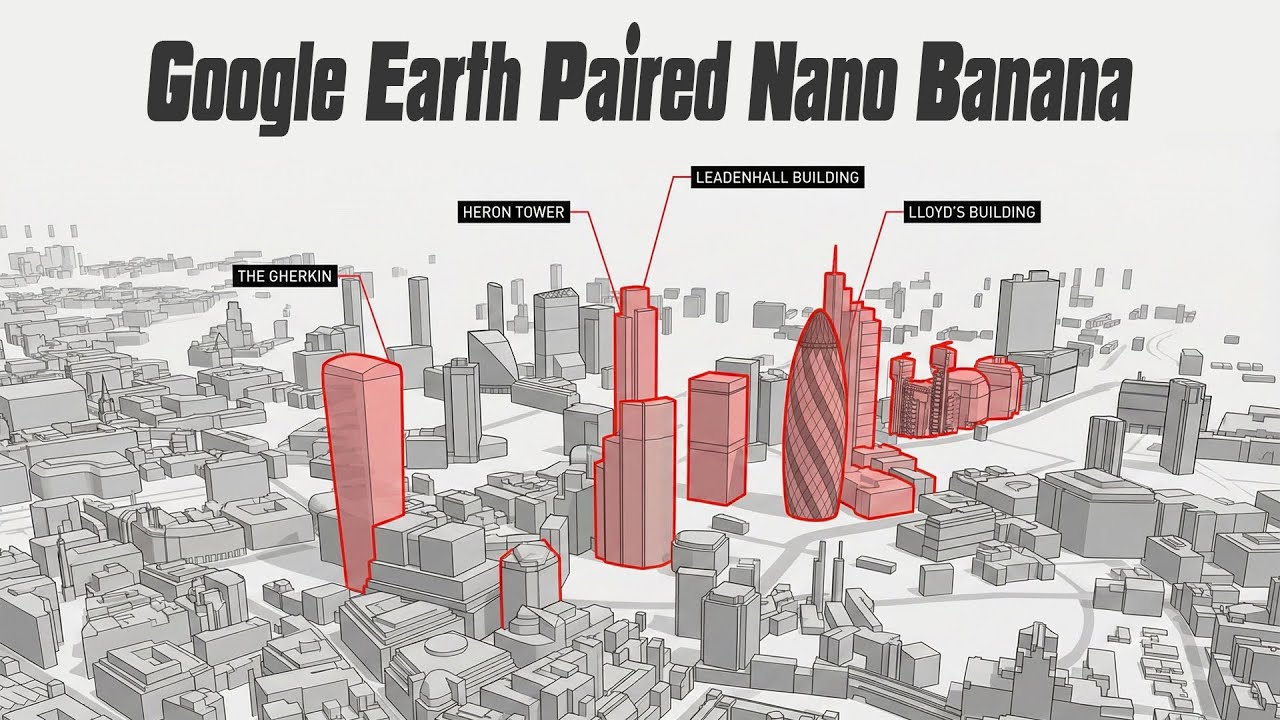
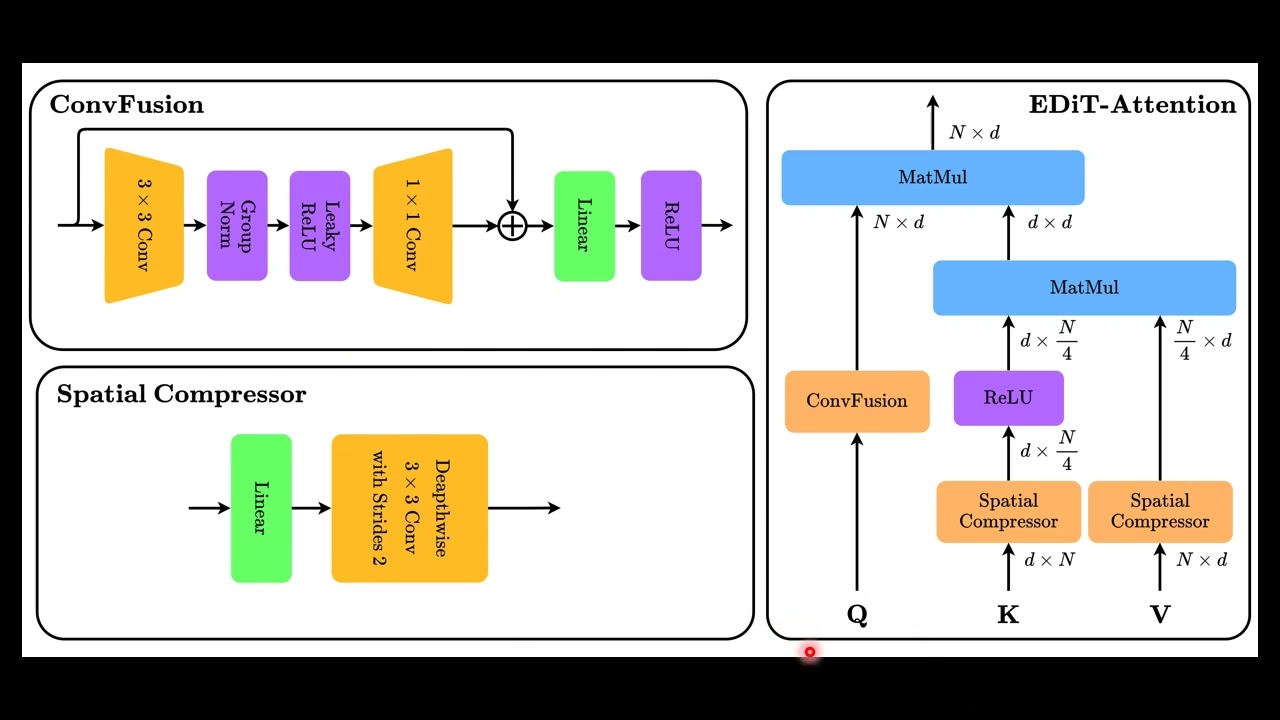
Efficient Diffusion Transformer (EDiT) Explained in 3 Minutes!
Автор: Kavishka Abeywardana
Загружено: 2026-02-15
Просмотров: 71
Описание:
🚀 Efficient Diffusion Transformers Explained | Linear Attention for Faster Text-to-Image Models
Diffusion Transformers are powering modern text-to-image systems like Stable Diffusion 3 and PixArt-Σ, but there’s a big problem ⚠️, attention computation becomes extremely expensive as image resolution increases.
In this video, we break down EDiT (Efficient Diffusion Transformers) and understand how it makes diffusion models faster without sacrificing image quality.
Instead of relying entirely on costly softmax attention, EDiT introduces linear compressed attention, combining convolutional processing with efficient attention mechanisms to scale diffusion models to higher resolutions.
🧠 What you’ll learn in this video
✨ Why diffusion transformers become computationally expensive
✨ Scaled dot-product attention vs linear attention
✨ Kernel decomposition using ReLU feature maps
✨ ConvFusion: convolution-based query generation
✨ Spatial compression for keys and values
✨ Joint attention in multimodal diffusion models
#machinelearning #diffusionmodels #generativeai #transformers #deeplearning #airesearch #stablediffusion #computervision #artificialintelligence #linearattention #DiffusionTransformer #MLResearch #neuralnetworks #aiexplained #techeducation #aiengineering
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: