FAFNIR: Accelerating Sparse Gathering by UsingEfficient Near-Memory Intelligent Reduction -- long
Автор: CASL Research Group at UMD CS
Загружено: 2021-03-04
Просмотров: 220
Описание:
Authors: Bahar Asgari, Ramyad Hadidi, Jiashen Cao, Da Eun Shim, Sung-Kyu Lim, Hyesoon Kim
IEEE International Symposium on High-Performance Computer Architecture (HPCA) 2021
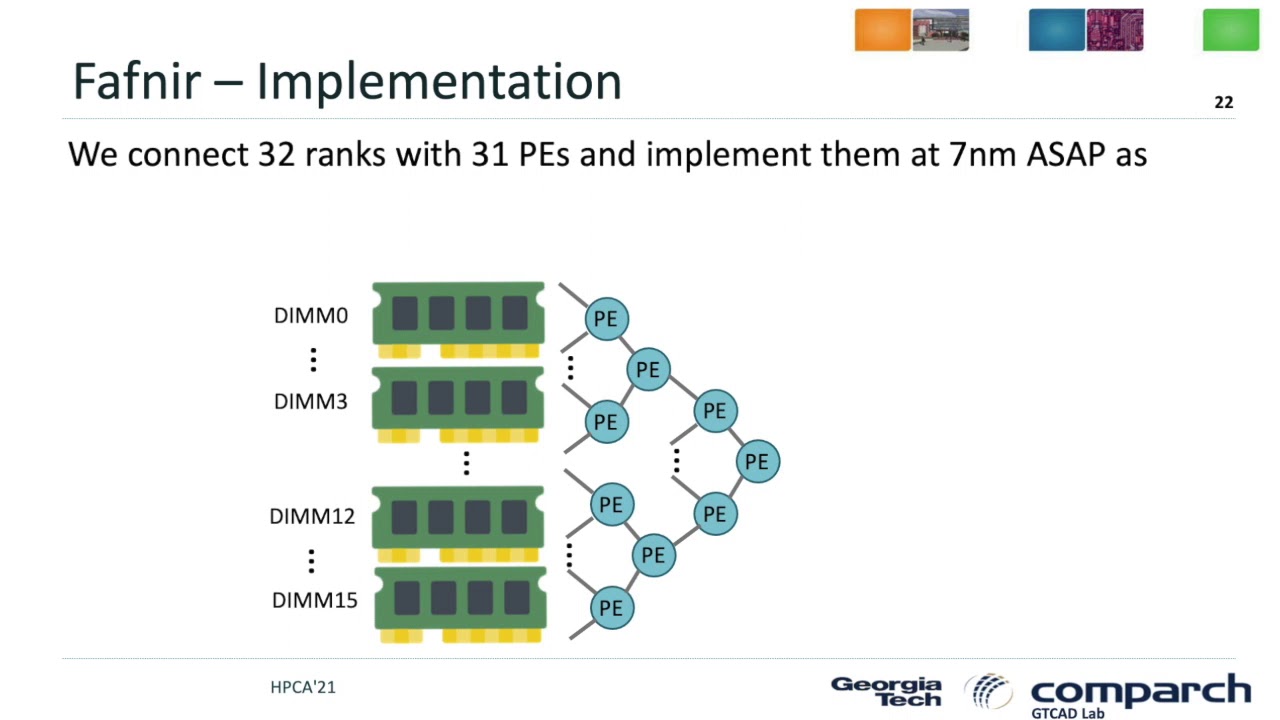
Abstract: Memory-bound sparse gathering, caused by irregular random memory accesses, has become an obstacle in several on-demand applications such as embedding lookup in recommendation systems. To reduce the amount of data movement, and thereby better utilize memory bandwidth, previous studies have proposed near-data processing (NDP) solutions. The issue of prior work, however, is that they either minimize data movement effectively at the cost of limited memory parallelism or try to improve memory parallelism (up to a certain degree) but cannot successfully decrease data movement, as prior proposals rely on spatial locality (an optimistic assumption) to utilize NDP. More importantly, neither approach proposes a solution for gathering data from random memory addresses; rather they just offload operations to NDP. We propose an effective solution for sparse gathering, an efficient near-memory intelligent reduction (Fafnir) tree, the leaves of which are all the ranks in a memory system, and the nodes gradually apply reduction operations while data is gathered from any rank. By using such an overall tree, Fafnir does not rely on spatial locality; therefore, it minimizes data movement by performing entire operations at NDP and fully benefits from parallel memory accesses in parallel processing at NDP. Further, Fafnir offers other advantages such as using fewer connections (because of the tree topology), eliminating redundant memory accesses without using costly and less effective caching mechanisms, and being applicable to other domains of sparse problems such as scientific computing and graph analytics. To evaluate Fafnir, we implement it on an XCVU9P Xilinx FPGA and in 7nm ASAP ASIC. Fafnir looks up the embedding tables up to 21.3x more quickly than the state-of-the-art NDP proposal. Furthermore, the generic architecture of Fafnir allows running classic sparse problems using the same 1.2mm^2 hardware up to 4.6x more quickly than the state of the art.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: