海力士 vs 三星:HBM4 記憶體牆的終局之戰
Автор: AI 耳邊風
Загружено: 2026-02-28
Просмотров: 21
Описание:
在 2026 年的 AI 算力基礎設施中,高頻寬記憶體(HBM) 已被正式確立為「算力燃料」。隨著 AI 模型參數邁向兆級(Trillions),運算效能的瓶頸不再僅是 GPU 核心的算力,而是資料從記憶體搬運到處理器的速度。HBM 透過結構性的封裝創新,成功打破了傳統的「記憶體牆(Memory Wall)」。
以下為 2026 年 HBM 技術演進、市場格局與競爭態勢的深度解析:
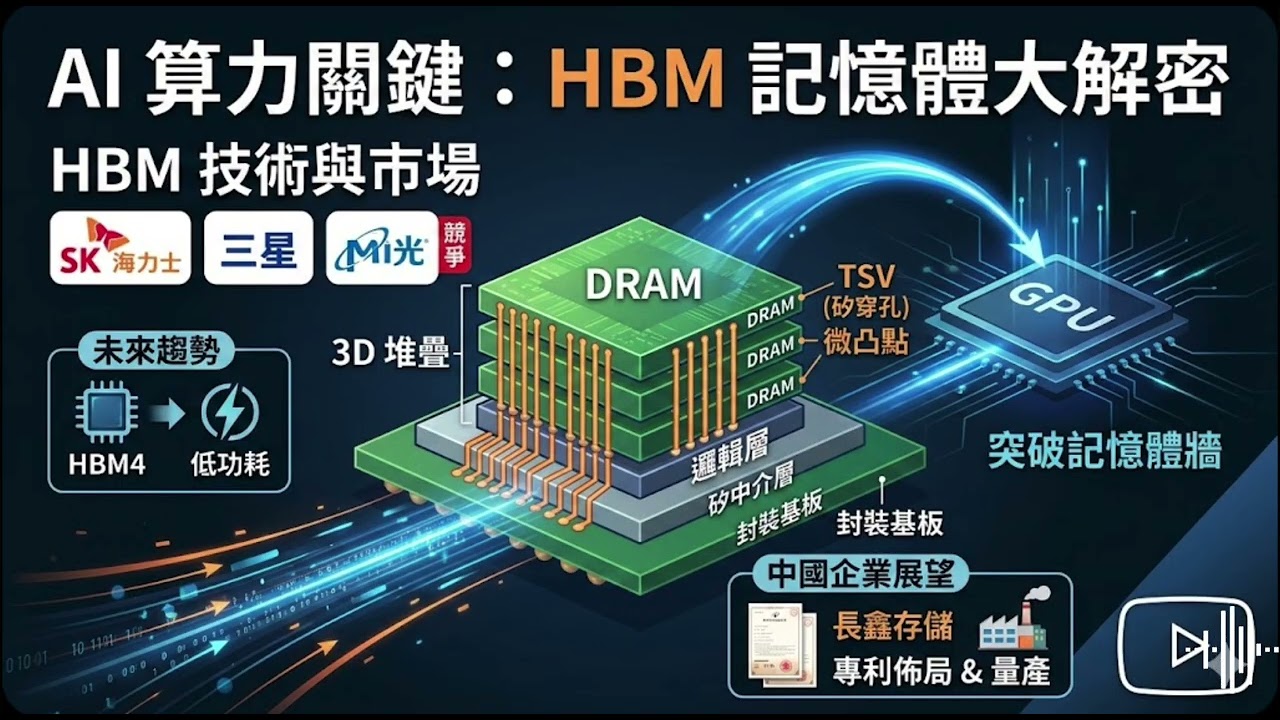
一、 技術核心:突破物理極限的 3D 堆疊
HBM 的技術優勢源於其**「垂直整合」**的架構,與傳統 DDR 記憶體相比,實現了頻寬與能效的質變:
TSV(矽穿孔)與微凸點(Microbump):
TSV:在 DRAM 晶片中鑽出數千個微孔,垂直穿透晶片並填充銅導線,大幅縮短了電子訊號的傳輸距離。
微凸點:連接層與層之間的微小導電焊球。2026 年,微凸點的直徑已微縮至 25$\mu$m 以下,這使得單顆 HBM 疊層能提供高達 1024-bit 的超寬 I/O 介面。
封裝工藝演進:
MR-MUF(液態環氧樹脂模封):SK 海力士的主力技術,透過液態材料滲透微小的間隙,解決了 12 層與 16 層高堆疊下的散熱難題。
混合鍵合(Hybrid Bonding):三星積極推動的新技術,取消了微凸點,直接讓金屬與金屬鍵合。這將進一步縮短晶片厚度,為 HBM4 的 16 層以上堆疊鋪路。
二、 2026 年市場轉折點:HBM4 與「基底邏輯層」革命
2026 年是 HBM 技術史上的重要里程碑,業界正從 HBM3e 邁向 HBM4:
2048-bit 超寬介面:HBM4 的匯流排位元寬度從 1024 翻倍至 2048-bit,這意味著單體頻寬將突破 2.0 TB/s,是 HBM3e 的 1.6 倍以上。
客製化基底邏輯層 (Base Die):在 HBM4 世代,最底層的邏輯控制晶片將改由**先進邏輯製程(如台積電 5nm 或 12nm)**代工。這使得 HBM 不再只是「被動存儲」,而是能直接在記憶體底層處理錯誤校正(ECC)或部分 AI 加速指令的「智慧記憶體」。
三、 全球三巨頭的 2026 競爭格局
目前 HBM 市場呈現高度壟斷,SK 海力士、三星與美光在 2026 年的戰略定位如下:
廠商 2026 年市場地位與進展 核心競爭優勢
SK 海力士 全球領跑者(市佔約 55%-60%)。率先實現 16 層 HBM4 量產,是 NVIDIA Rubin 平台的核心供應商。 MR-MUF 技術領先,與台積電、NVIDIA 深度綁定。
三星電子 強勢追趕者。主攻混合鍵合技術,力求在 HBM4 世代反超良率,並積極爭取客製化 HBM 訂單。 具備 IDM 優勢(自家製程+封裝),資本與技術開發速度驚人。
美光 (Micron) 效能尖兵。雖然產能規模較小,但以極佳的每瓦效能比在高端伺服器市場佔有一席之地。 專注於高能源效率設計,擴產進度已排至 2027 年。
四、 中國本土企業展望:長鑫存儲(CXMT)的突破
在國產替代與 AI 晶片需求推動下,中國記憶體龍頭長鑫存儲已取得顯著進展:
HBM3 實現量產:長鑫存儲已向華為等國內大客戶交付 16nm 製程的 HBM3 樣品,預計 2026 年實現全面量產。
技術追趕:儘管目前進度落後國際一線廠商約 3 至 4 年,但其 16nm 製程良率已接近成熟水平(據報突破 80%),並計劃於 2027 年開發 HBM3E。
專利與資本佈局:長鑫存儲已啟動 IPO 計畫,估值預計突破 3,000 億人民幣。透過在上海建立專屬的 HBM 後段封裝廠,試圖建立從 DRAM 到 2.5D/3D 封裝的完整自主供應鏈。
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















![🔴 EXPRESS BIEDRZYCKIEJ | MAGDALENA SOBKOWIAK-CZARNECKA, JERZY MAREK NOWAKOWSKI [NA ŻYWO]](https://imager.clipsaver.ru/w2r6BcYyy7E/max.jpg)