Introduction to ACT for autonomous driving | VLA for autonomous driving bootcamp | Lecture 2
Автор: Vizuara
Загружено: 2026-04-06
Просмотров: 2295
Описание:
Get full access to our entire robotics course here: https://minor-robotics.vizuara.ai/
Get full access to VLA course here: https://vizuara.ai/courses/vision-lan...
In this second lecture of the Vision-Language-Action for Autonomous Driving bootcamp, we go deep into one of the most important architectures for modern robot control and imitation learning: the Action Chunking Transformer (ACT). In this session, we move beyond simple vision-only driving and begin building an ACT-based self-driving policy inside our simulator, where the vehicle must not only drive but also respond correctly to language intent such as taking the left path or the right path at a fork in the road. The lecture also introduces the role of the Conditional Variational Autoencoder (CVAE) and explains why it becomes important when the same visual scene can correspond to multiple valid actions, which is exactly the kind of multimodal behavior we encounter in autonomous driving and robotics.
We begin by contrasting two environments: a curved road, where language is not necessary because the only goal is to keep driving along the road, and a forked road, where the same visual input can lead to different correct actions depending on the language instruction. From there, the lecture builds intuition step by step, starting from a simple vision-to-action CNN policy and showing how image inputs can be transformed into action probabilities using convolution layers, pooling, MLPs, and sigmoid outputs for multi-action control such as forward + left. This creates the foundation for understanding why ACT is needed when one-step action prediction is not enough.
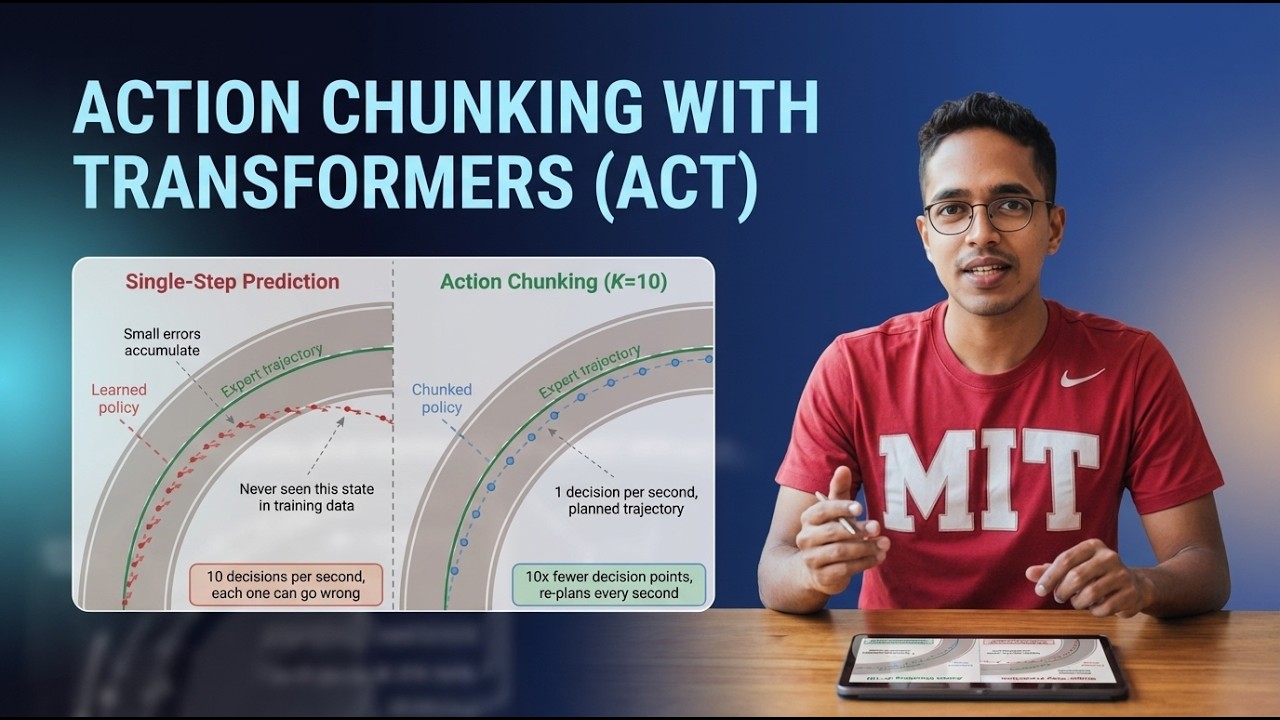
The core of the lecture focuses on the Action Chunking Transformer architecture, where visual observations are first encoded using CNNs, converted into tokens, enriched with positional information, and then passed through a transformer encoder-decoder pipeline to predict multiple future actions as a chunk instead of a single action at one time step. You will also see how this evolves into a full Vision-Language-Action (VLA) setup by adding language embeddings, and why the most complete and capable version is the combination of ACT + CVAE + language conditioning. The lecture further compares multiple experimental setups across curved-road and forked-road scenarios, including vision-only policies, ACT without language, ACT with language, ACT with CVAE, and the full ACT + CVAE + language pipeline, giving strong intuition for why multimodal decision-making requires richer architectures.
If you want to understand how modern VLA systems bridge the gap between perception, language understanding, and action generation, this lecture is a very practical and beginner-friendly walkthrough that connects first-principles intuition with an actual working self-driving simulator project.
What you will learn in this lecture:
What Action Chunking Transformer (ACT) is and why it is useful in robotics
How to build an ACT-based self-driving policy in simulation
Difference between curved-road and forked-road driving tasks
Why vision-only models fail in ambiguous multimodal scenarios
How language intent changes autonomous driving decisions
Why sigmoid is used instead of softmax for multi-action driving control
How ACT predicts future action chunks instead of one action at a time
Why Conditional Variational Autoencoder (CVAE) is needed for multimodal behavior
Comparison of multiple policy variants: vision-only, ACT, ACT + language, ACT + CVAE, and full VLA
How ACT + CVAE + language forms a proper Vision-Language-Action pipeline for autonomous driving
If you enjoy deep, first-principles AI content that goes from intuition to implementation, subscribe to Vizuara for more lectures on robotics, VLA systems, transformers, and autonomous driving.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: