AI Talk Việt | Ep21 – Tại Sao Vision Transformer Đang Dần Thay Thế CNN Trong AI?
Автор: AI Talk Việt
Загружено: 2025-11-06
Просмотров: 266
Описание:
Vision Transformer (ViT) – khi sức mạnh của Transformer được mang vào lĩnh vực thị giác máy tính.
Tập podcast này giúp bạn hiểu vì sao ViT đang dần thay thế CNNs trong nhiều tác vụ AI, và cách cơ chế self-attention giúp mô hình “nhìn” hình ảnh theo cách hoàn toàn mới.
Timestamp:
00:17 – Mở đầu về Vision Transformer (ViT)
01:13 – Bối cảnh ra đời của ViT
02:04 – Transformer trong NLP và cơ chế Self-Attention
03:28 – Thách thức khi áp dụng mô hình chuỗi (văn bản) cho dữ liệu hình ảnh 2D.
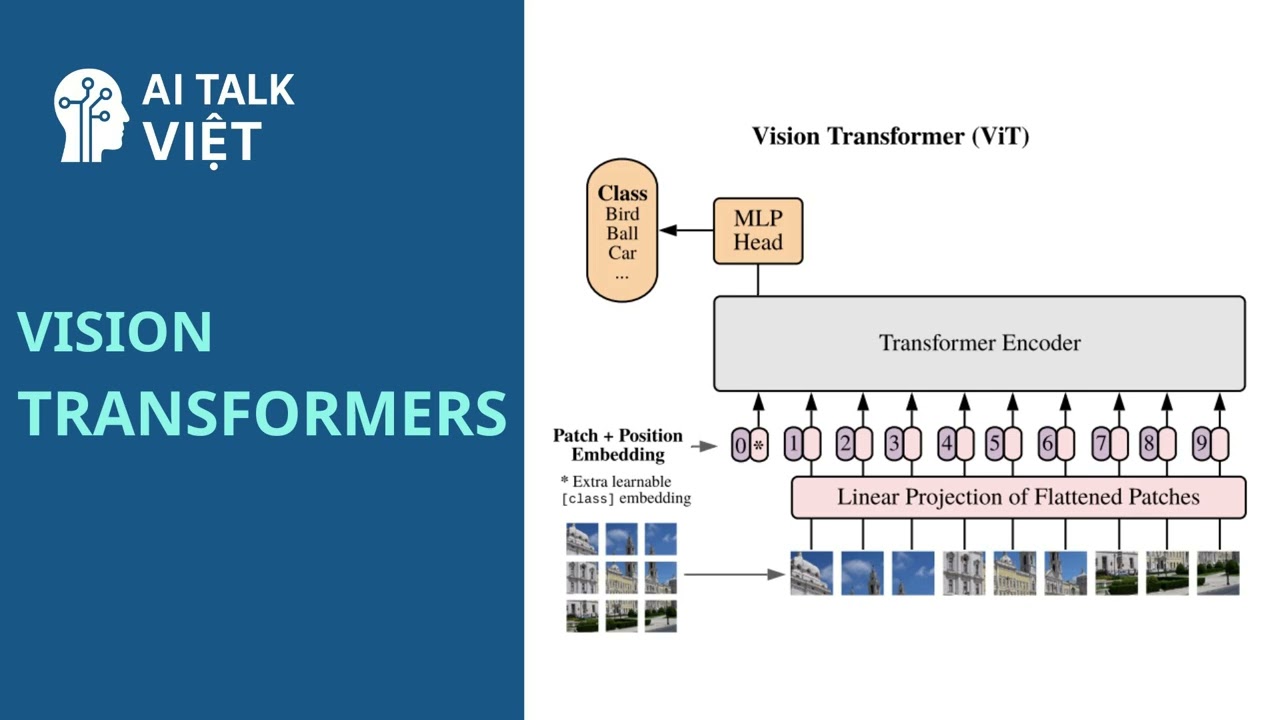
04:09 – Cách hoạt động của ViT
08:10 – So sánh ViT và CNN
10:32 – Hiệu suất huấn luyện và khả năng mở rộng
12:06 – Ứng dụng thực tế của ViT
Nội dung chính:
• Kiến trúc Vision Transformer – cách chia hình ảnh thành “patches” và xử lý như chuỗi dữ liệu.
• Cơ chế Multi-Head Attention và Positional Embedding trong ViT.
• So sánh chi tiết ViT và CNNs: ưu, nhược điểm, và hiệu quả trên dữ liệu lớn.
• Ứng dụng thực tế: phân loại, phân đoạn, captioning, anomaly detection, lái xe tự hành…
• Vì sao ViT trở thành nền tảng cho thế hệ thị giác AI mới.
Một tập không thể bỏ qua nếu bạn muốn hiểu cách AI “nhìn thấy” thế giới qua đôi mắt Transformer.
#AITalkViet #VisionTransformer #ViT #Transformer #ComputerVision #CNN #DeepLearning #ImageClassification #AI #MachineLearning #NeuralNetworks #AttentionMechanism #AIResearch #Podcast #ArtificialIntelligence
Toàn bộ nội dung thuộc bản quyền © 2025 bởi kênh AI Talk Việt. Không được sao chép, tái sử dụng hoặc re-upload dưới bất kỳ hình thức nào.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: