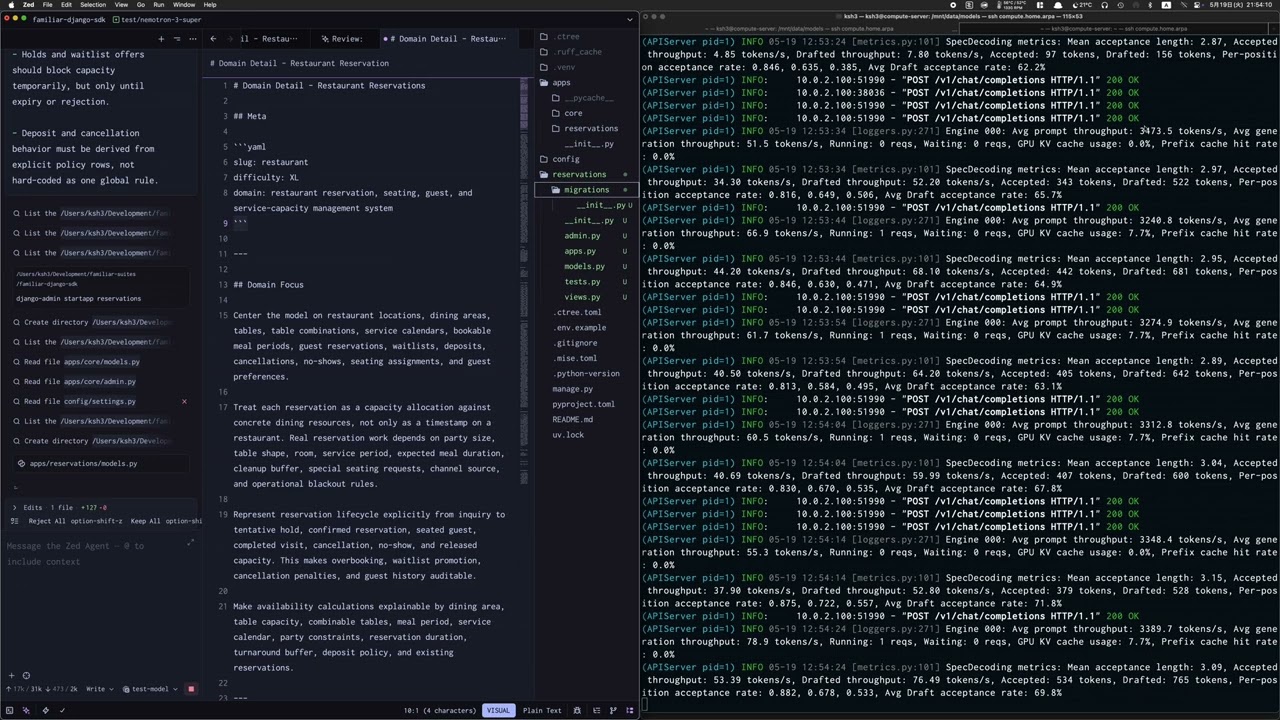
Nemotron 3 Super 120B NVFP4 on RTX PRO 6000: 150 tok/s with vLLM MTP
Автор: ksh3
Загружено: 2026-05-19
Просмотров: 77
Описание:
Running NVIDIA Nemotron 3 Super 120B A12B NVFP4 locally on a single RTX PRO 6000 Blackwell 96GB GPU with vLLM 0.21.0.
Good for:
Fast response
Short-to-medium outputs
Tool-heavy orchestration
Single GPU inference
64K context + 569K token KV cache
Configuration:
Model: NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
Runtime: vLLM 0.21.0
GPU: RTX PRO 6000 Blackwell 96GB
Quantization: ModelOpt NVFP4 / FP8 mixed
KV cache: FP8
Context length: 65,536
Tensor parallel: 1
Speculative decoding: MTP, 3 speculative tokens
MoE backend: Marlin
Attention backend: FlashInfer
Observed results:
Generation throughput: up to 152 tok/s
Typical active generation: around 60 tok/s+
Mean MTP acceptance length: 3.26
Average draft acceptance rate: 76.4%
Best draft acceptance rate: 98.9%
GPU memory used for model load: 75.07 GiB
This is a local homelab/workstation inference test on a single 96GB Blackwell GPU.
Command used:
```bash
podman run --rm -it \
--name grandpa-test \
--device nvidia.com/gpu=0 \
--shm-size 8g \
-p 8000:8000 \
-v /mnt/data/models:/hf/hub:ro \
-e HF_HOME=/hf \
-e HF_HUB_CACHE=/hf/hub \
-e HF_HUB_OFFLINE=1 \
-e TRANSFORMERS_OFFLINE=1 \
-e TORCH_CUDA_ARCH_LIST=12.0 \
-e VLLM_TARGET_DEVICE=cuda \
-e VLLM_NVFP4_GEMM_BACKEND=marlin \
-e VLLM_FLASHINFER_ALLREDUCE_BACKEND=trtllm \
-e VLLM_USE_FLASHINFER_MOE_FP4=1 \
registry.home.arpa/vllm/vllm-openai:v0.21.0-ubuntu2404 \
--model /hf/hub/models--nvidia--NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4/snapshots/bd90f177c8c69d8f3969c61e7e8f1afaba57ae61 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name test-model \
--dtype auto \
--kv-cache-dtype fp8 \
--tensor-parallel-size 1 \
--trust-remote-code \
--gpu-memory-utilization 0.90 \
--enable-chunked-prefill \
--max-num-seqs 1 \
--max-model-len 65536 \
--moe-backend marlin \
--async-scheduling \
--mamba-ssm-cache-dtype float16 \
--quantization fp4 \
--speculative-config '{"method":"mtp","num_speculative_tokens":3,"moe_backend":"triton"}' \
--reasoning-parser-plugin /hf/hub/models--nvidia--NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4/snapshots/bd90f177c8c69d8f3969c61e7e8f1afaba57ae61/super_v3_reasoning_parser.py \
--reasoning-parser super_v3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--override-generation-config '{"temperature":0.7,"top_p":0.95,"top_k":45}'
```
```log
Generation throughput: 152.2 tok/s
Mean acceptance length: 3.66
Avg Draft acceptance rate: 88.6%
Generation throughput: 143.8 tok/s
Mean acceptance length: 3.68
Avg Draft acceptance rate: 89.5%
Generation throughput: 125.8 tok/s
Mean acceptance length: 3.84
Avg Draft acceptance rate: 94.8%
Generation throughput: 97.8 tok/s
Mean acceptance length: 3.97
Avg Draft acceptance rate: 98.9%
```
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: