Google Cloud Managed Lustre for LLM Inference: Cut GPU Waste by 50%
Автор: DDN
Загружено: 2026-05-08
Просмотров: 80
Описание:
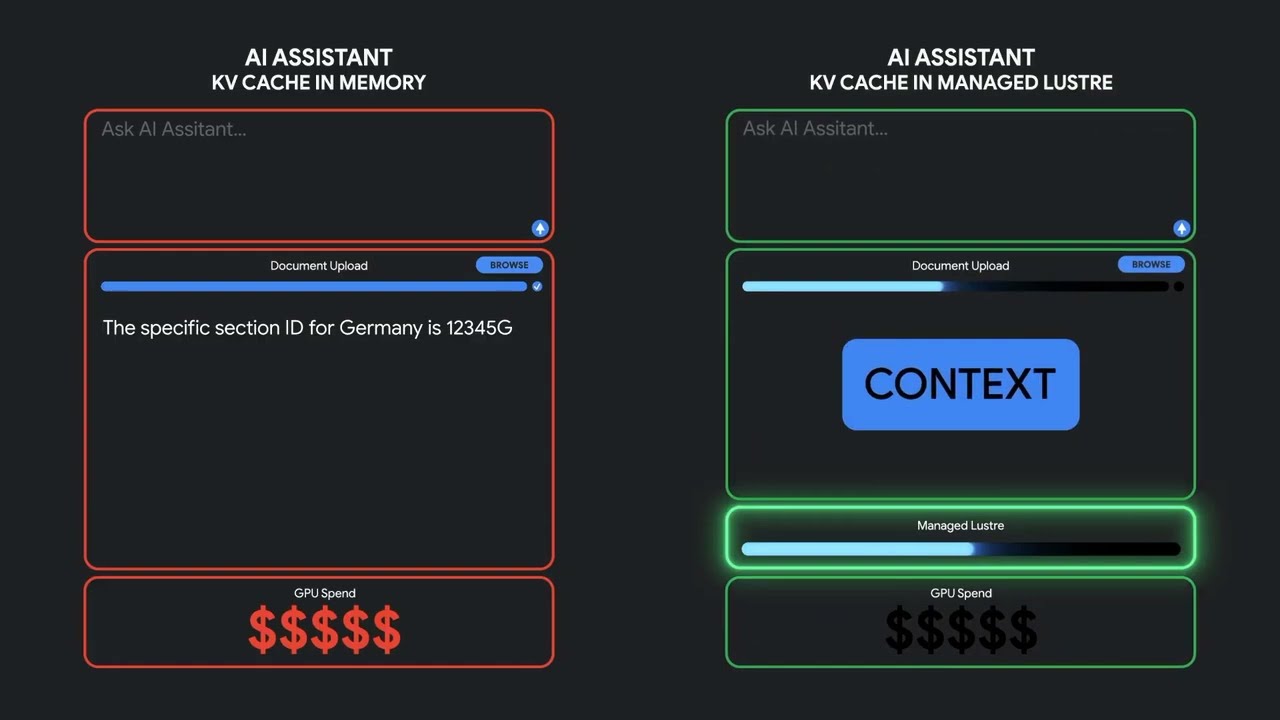
Managed Lustre helps LLMs reload saved context instead of recalculating expensive analysis from scratch.
This video explains how Google Cloud Managed Lustre can reduce inference costs for large multimodal workloads like 100-page legal contracts by persisting KV cache state outside GPU memory.
Key takeaways:
Why large LLM prompts create heavy GPU memory pressure
How KV cache eviction forces redundant recomputation
How Managed Lustre preserves conversation “brain state”
Why reloading context can enable subsecond responses
How fleet-scale inference can reduce wasted GPU compute
How this architecture can cut inference TCO by up to 50%
Watch to see how Managed Lustre helps keep GPUs focused on productive work instead of repeating the same math.
#ManagedLustre #GoogleCloud #LLMInference #GPUOptimization #KVCaching #AIInfrastructure #CloudAI
***************************************************
SUBSCRIBE TO OUR CHANNEL:
/ @ddnintelligence
VISIT OUR WEBSITE:
https://www.ddn.com/
***************************************************
DDN SOCIAL:
LinkedIn: / ddn
Twitter: https://x.com/DDNintelligence
Instagram: / ddnintelligence
Facebook: / ddnintelligence
***************************************************
WHAT IS DDN?
At DDN, we are pioneers in high performance data storage and management, dedicated to delivering innovative solutions that empower organizations across the globe. Our commitment to excellence, coupled with our cutting-edge technology, enables us to drive performance, scalability and reliability for our clients. Discover how our expertise and passion for data are transforming industries and shaping the future.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: