Основите на машинното обучение
Автор: AI Училище
Загружено: 2026-02-19
Просмотров: 18
Описание:
Истинската магия зад ИИ: Как компютрите се учат (и защо данните се "чистят")? 🤖🧹
В предишните видеа разбрахме какво са алгоритмите и Големите данни. Днес ще ги обединим, за да разкрием най-мощната технология на нашето време – Машинното обучение (Machine Learning).
Ето какво точно ще научите в този урок:
1. Разликата между ИИ, Алгоритми и Машинно обучение Ще разбием мита, че всеки написан код е изкуствен интелект.
• Ще разберете защо един алгоритъм, който просто сортира списък с клиенти по държава, не притежава истинска "интелигентност".
• Ще научите, че изкуственият интелект е широкият термин, докато машинното обучение е неговият основен двигател в наши дни.
• За разлика от старите системи (като шах компютъра DeepBlue), които следват твърдо зададени правила, системите за машинно обучение имат способността да се адаптират и учат с времето. Пример: Face ID на Apple, който е обучен с хиляди човешки лица, за да се научи да разпознава точно вашето.
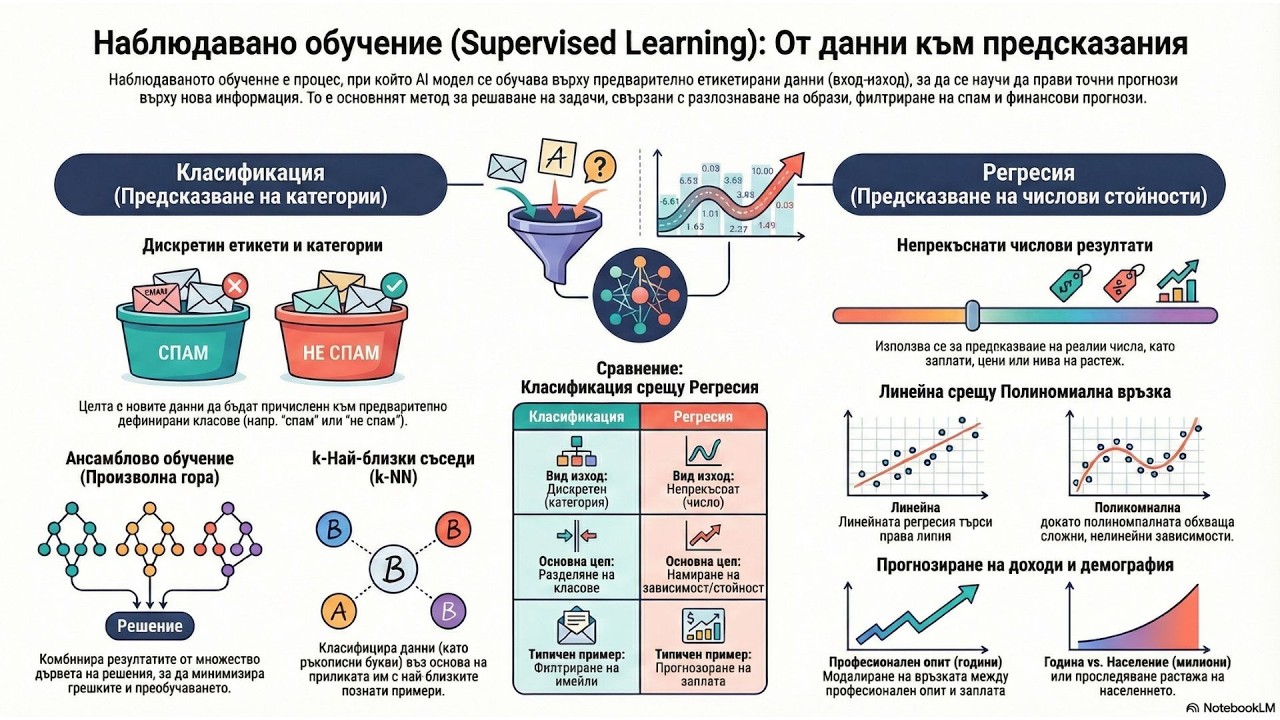
2. Суровината: Как машините четат таблици? За да се обучава, алгоритъмът се нуждае от информация, която най-често е структурирана като таблични данни. Ще научите какво са признаци (features) и как се делят на два основни вида:
• 🔢 Числови признаци: Променливи, изразени с цифри (например възраст на клиента или сума на покупката).
• 🔠 Категориални признаци: Променливи под формата на текст или прости отговори "да/не" (например име на клиента или дали той е редовен купувач).
3. Тайната на експертите: Предварителна обработка (Data Preprocessing) Машините не могат да се учат от "разхвърляни" и хаотични данни. Ще ви преведем през 4-те задължителни стъпки, чрез които специалистите подготвят информацията:
• 🧹 Почистване (Cleaning): Идентифициране на грешки, премахване на дублиращи се записи и попълване на липсваща информация (например записване на средната възраст, ако липсва такава), за да не прави моделът грешни изводи.
• ⚖️ Скалиране (Scaling): Уеднаквяване на мащаба. Как да приравним клиентска анкета с оценки от 1 до 5 и друга с оценки от 1 до 10? Скалирането ги превръща в десетични числа между 0 и 1 (например 5/10 става 0.5), за да не натежава нито една метрика несправедливо.
• 📊 Нормализация (Normalizing): Премахване на екстремни аномалии (например необичайно голям пик на продажби в един конкретен ден), за да може данните да следват стандартно разпределение и да не изкривяват генералната картина.
• 🔐 Кодиране (Encoding): Тъй като алгоритмите не могат да обработват думи, категориалните признаци (като текст "електроника" или "облекло") се преобразуват в числов формат (често 1 или 0), за да бъдат разбрани от машината.
Гледайте видеото, за да разберете защо "магичният" ИИ всъщност разчита на огромно количество ръчна работа по подреждане и почистване на данните!
--------------------------------------------------------------------------------
Кратък откъс за Shorts/Reels/TikTok (Hook):
🧠 Знаеш ли разликата между алгоритъм и машинно обучение? Обикновеният алгоритъм само следва инструкции – като например да сортира списък по азбучен ред. Машинното обучение обаче се учи и се променя с времето! Точно така работи Face ID на телефона ти. Но за да стане "умен", компютърът има нужда от перфектно чисти данни. В новото видео ти показвам 4-те стъпки на предварителната обработка, през които минава всяка информация, преди изобщо да стигне до ИИ. Линк в описанието! 👇
Как се различават машинното обучение и изкуственият интелект?
Какво представляват числовите и категориалните признаци в данните?
Защо почистването и скалирането са критични за моделите?
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:




![Биология поведения человека. Лекция #1. Введение [Роберт Сапольски, 2010. Стэнфорд]](https://imager.clipsaver.ru/ik9t96SMtB0/max.jpg)