NVIDIA Just Made Running 128K Token Models Actually Possible (KVzap Breakdown)
Автор: AISoftScope
Загружено: 2026-01-17
Просмотров: 15
Описание:
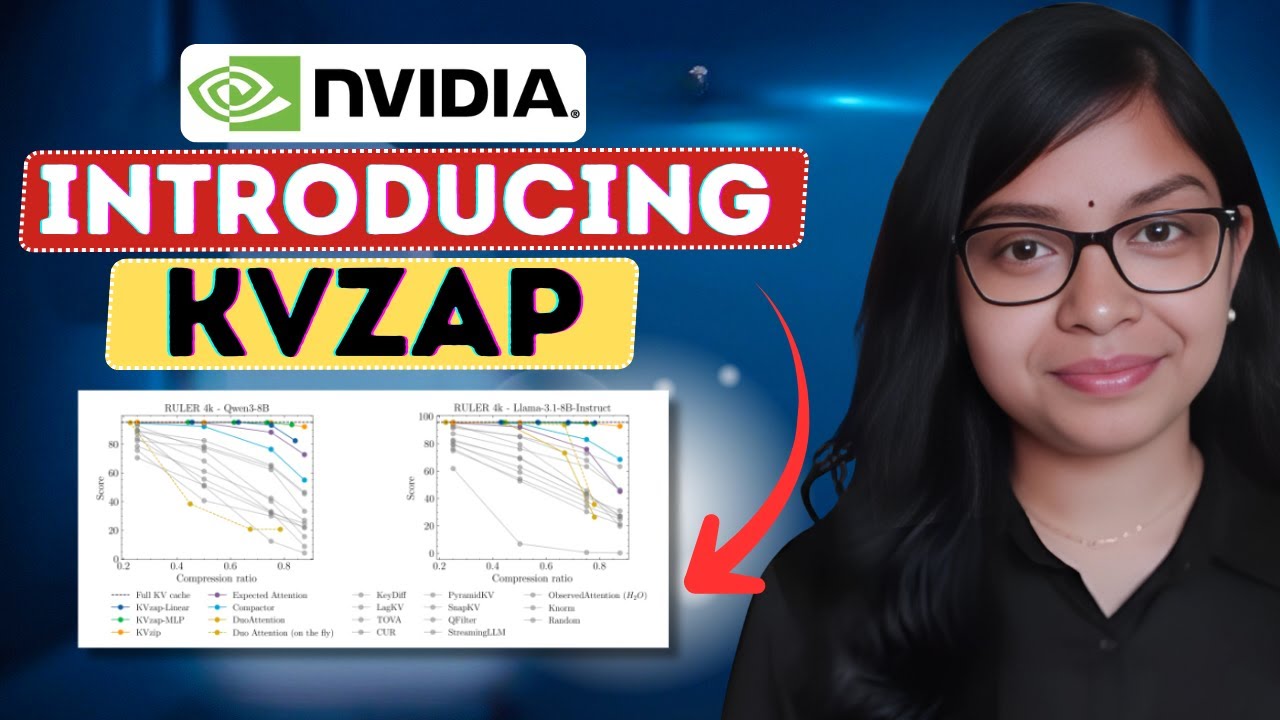
NVIDIA just open-sourced KVzap, and it's already changing how we run large AI models. This breakthrough compresses KV cache memory by 2-4x with almost zero accuracy loss - solving the biggest bottleneck in long-context AI.
In this video, I break down:
✅ How KVzap cuts memory use by up to 75% while maintaining performance
✅ The exact benchmarks: RULER, LongBench, and AIME25 results across Qwen3-8B, Llama 3.1 8B, and Qwen3-32B
✅ Why this matters: a Llama 65B model with 128k tokens needs 335GB just for cache - KVzap slashes that
✅ How the surrogate model system works (linear layer vs MLP variants)
KVzap vs competitors: Expected Attention, H2O, SnapKV, PyramidKV
✅ Real compression ratios: 2.7-3.5x average with threshold-based adaptive pruning
✅ Why it tops the KVpress Leaderboard for both prefilling AND decoding
✅ The 1.1% compute overhead secret that makes it practical
✅ How to implement it right now (it's fully open-source on GitHub)
🔗 LINKS:
Official Paper: https://arxiv.org/pdf/2601.07891
GitHub Repo: https://github.com/NVIDIA/kvpress/tre...
💬 What do you think about KV cache compression becoming the new battleground in AI? Drop your thoughts below!
🔔 Subscribe for more AI breakthrough breakdowns
👍 Like if this helped you understand KVzap
#NVIDIA #KVzap #AI #MachineLearning #LLM #KVCache #OpenSource #DeepLearning #TechNews #AINews
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















