Тонкая настройка LLM через обучение с подкреплением и верифицируемые награды
Автор: Yersham
Загружено: 2026-02-18
Просмотров: 229
Описание:
• How to Fine-tune LLMs with RLVR (OpenAI’s ...
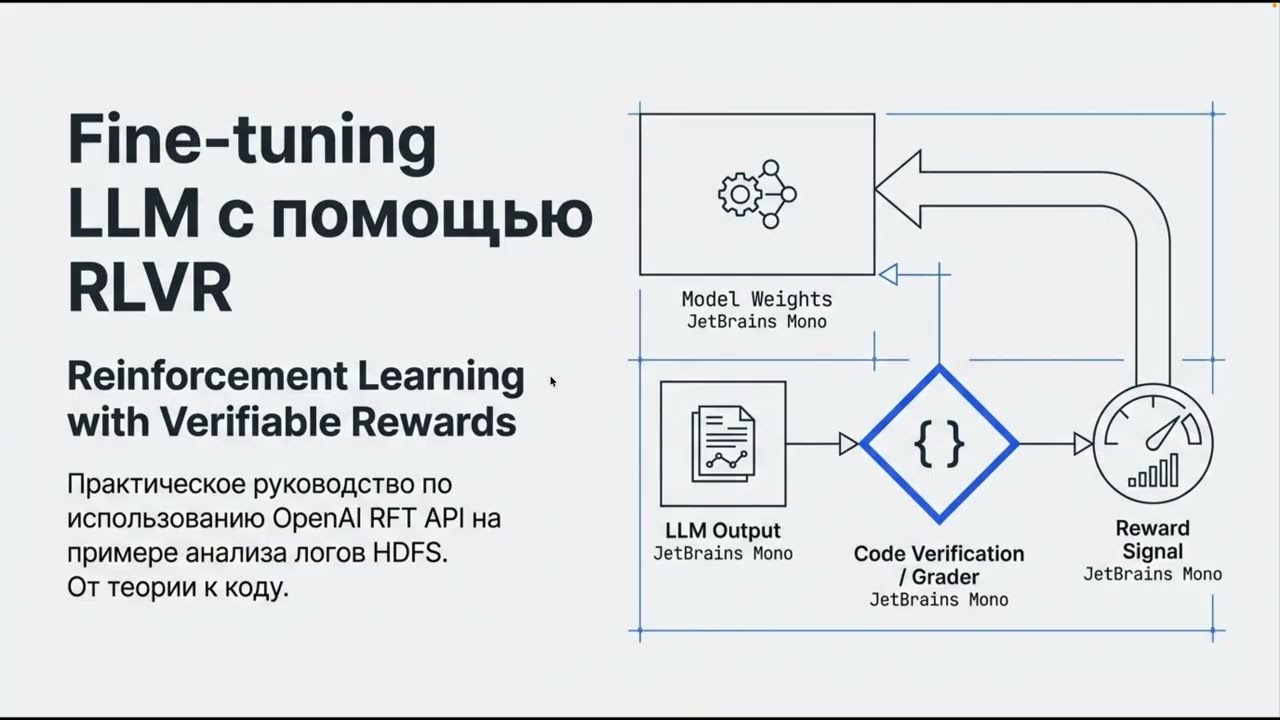
Этот текст представляет собой подробный обзор методики тонкой настройки языковых моделей с использованием обучения с подкреплением на основе проверяемых вознаграждений (RLVR). Автор сравнивает этот подход с традиционным обучением на предпочтениях людей, отмечая, что новый метод позволяет моделям самостоятельно рассуждать для достижения правильного результата. В качестве практического примера демонстрируется процесс обучения модели GPT-4o mini для выявления аномалий в системных логах через API OpenAI. Особое внимание уделяется структурированию данных, созданию программного оценщика ответов и анализу метрик эффективности, таких как F1-score. В заключении рассматриваются высокая стоимость облачных вычислений и преимущества перехода на открытые инструменты для полного контроля над процессом логического вывода.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















