GPU Warps Explained: How SIMT Really Works Under the Hood (Visual Deep Dive) | M2L3
Автор: Parallel Routines
Загружено: 2026-01-16
Просмотров: 649
Описание:
How can a GPU execute thousands of threads at once—and why does a single instruction control all of them?
In Module 2 · Lesson 3, this video explains SIMT execution (Single Instruction, Multiple Threads) from first principles, connecting the programming model to real GPU hardware. We begin with scalar execution, build intuition through SIMD parallelism, and then show how GPUs scale this model using warps, batching, and streaming multiprocessors.
Using step-by-step visuals, we trace how a simple kernel:
Maps threads to data
Computes global indices
Loads from memory
Executes arithmetic in lockstep
Writes results back to global memory
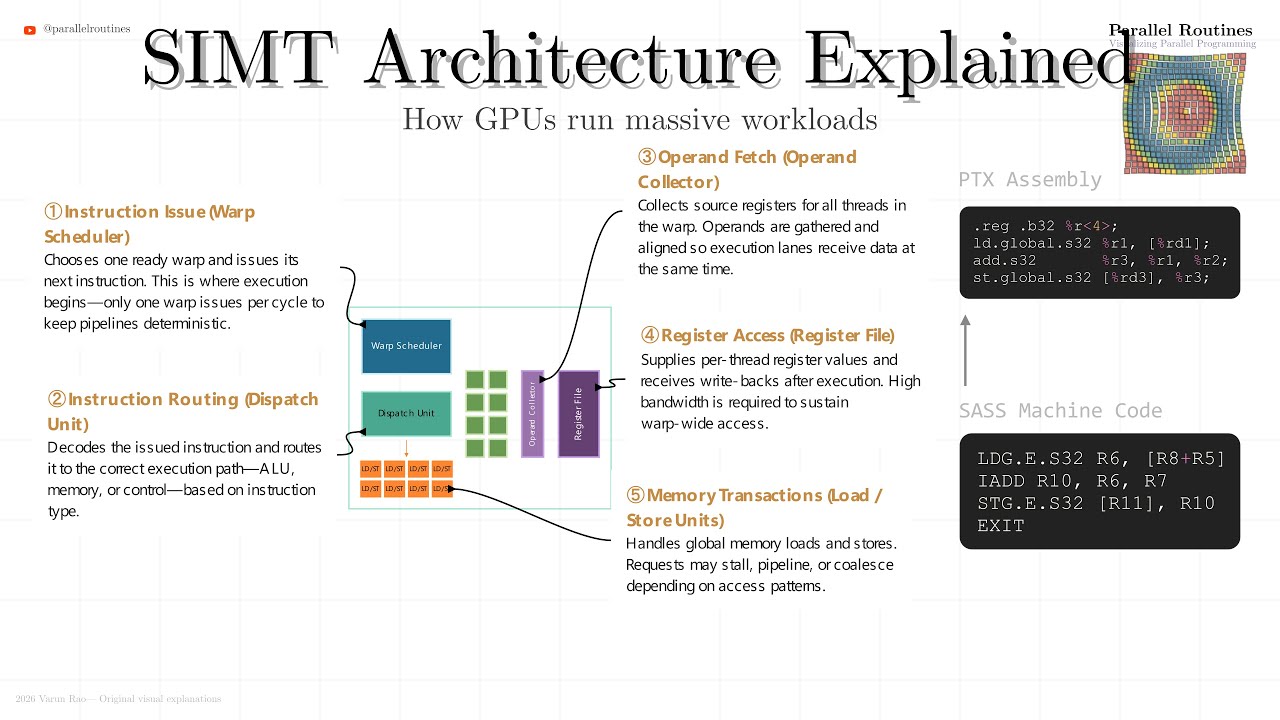
We then move below the abstraction layer into the Streaming Multiprocessor (SM), examining warp scheduling, execution partitions, register files, load/store units, and how memory latency is hidden through massive parallelism.
This lesson builds the mental model needed to understand:
Why GPUs require thousands of threads
How SIMD becomes SIMT
Why do warps stall on memory
How hardware, not software, manages execution complexity
📺 Related videos
GPU Memory Hierarchy Explained: Registers, Shared Memory, L2, HBM, and PCIe (Visual) | M2L2
• GPU Memory Hierarchy Explained: Registers,...
GPU Memory Coalescing Explained (Visual)
Why GPU Shared Memory Becomes Slow | Bank Conflicts Explained
⏱️ Timeline Overview
00:00 — How GPUs execute thousands of threads
00:18 — Scalar execution: the sequential baseline
00:39 — SIMD parallelism and execution lanes
00:55 — SIMD masking and inactive lanes
01:45 — Batching data into parallel execution groups
02:04 — Kernel programming model intuition
03:44 — Warps, scheduling, and SM execution
04:08 — SM partitions and execution units
04:55 — Register files and per-thread state
05:15 — Load/store units and memory flow
05:31 — PTX, SASS, and instruction expansion
06:16 — Stepping through real instruction execution
07:37 — Memory latency and warp stalling
08:45 — Arithmetic execution in lockstep
09:18 — Stores and warp completion
09:32 — Final SIMT execution takeaways
📌 Final Takeaway
GPUs do not execute “many instructions at once.”
They execute one instruction across many threads, repeatedly, at a massive scale.
SIMT is the architectural trick that turns simple SIMD execution into the engine behind graphics, HPC, and AI.
Understanding this model is the key to reasoning about GPU performance.
#GPUArchitecture #SIMT #Warps #CUDA #ParallelComputing #ComputerArchitecture #HighPerformanceComputing
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: