ISCA's 2025 DML Walkthrough: How to Create a Discourse Dataset from X/Twitter (Challenge #1)
Автор: ISCA Indiana University
Загружено: 2025-07-29
Просмотров: 104
Описание:
This tutorial offers a complete walkthrough of Challenge #1 of the 2025 Datathon and Machine Learning Competition on Antisemitism, hosted by Indiana University’s Institute for the Study of Contemporary Antisemitism (ISCA). It guides participants through the key steps for collecting, processing, and annotating social media data from X (formerly Twitter) as part of a hands-on hate speech detection task.
The recording covers all technical and methodological components, including how to search and scrape posts using Bright Data, pre-process the data in Google Colab, and structure your annotations using the Annotation Portal.
All necessary tools, links, and templates are provided below to support an independent and structured workflow.
Chapters:
01:00 Agenda & Objectives
01:47 Prerequisites & Setup
02:26 What is the Datathon?
02:57 Instructions for Challenge #1
03:53 Working With X's Advanced Search Function
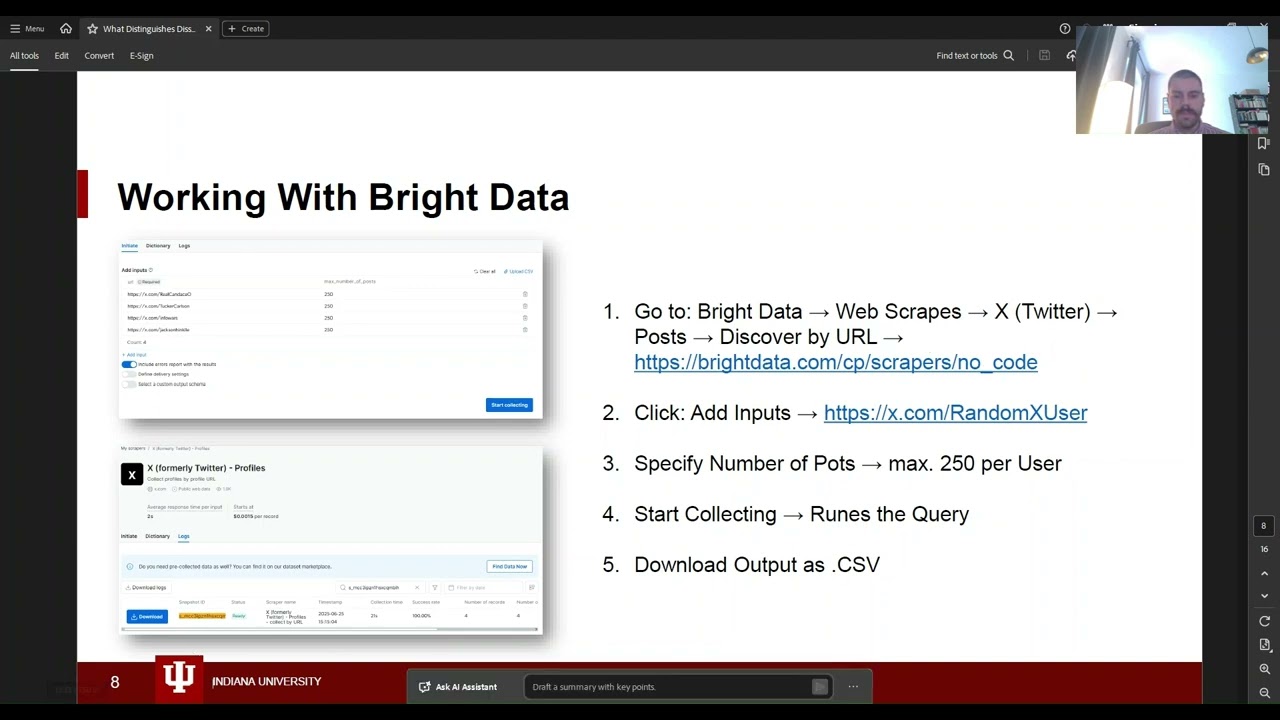
08:34 Working With Bright Data
11:28 Working With Google Colab
17:28 Annotation Portal Walkthrough
23:02 Setting Up An Annotation Scheme
29:02 Download Annotated Dataset
Useful Resources and Links
Annotation Portal: https://annotate.osome.iu.edu
Challenge Description (PDF): https://github.com/damieh1/datathon_2...
GitHub ReadMe (tools & setup): https://github.com/AnnotationPortal/D...
Bright Data Scraper (no code): https://brightdata.com/cp/scrapers/no...
Google Colab (preprocessing script): https://colab.research.google.com/git...
Download the full slide deck: https://github.com/damieh1/datathon_2...
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: