How to Inference Gemma 4 Locally on Mac (M1 8GB to M5 MAX) with SwiftLM
Автор: Sharp AI
Загружено: 2026-04-05
Просмотров: 591
Описание:
Running massive LLMs like Gemma 4-26B directly on Apple Silicon just became dramatically faster—and more memory efficient. https://github.com/SharpAI/SwiftLM
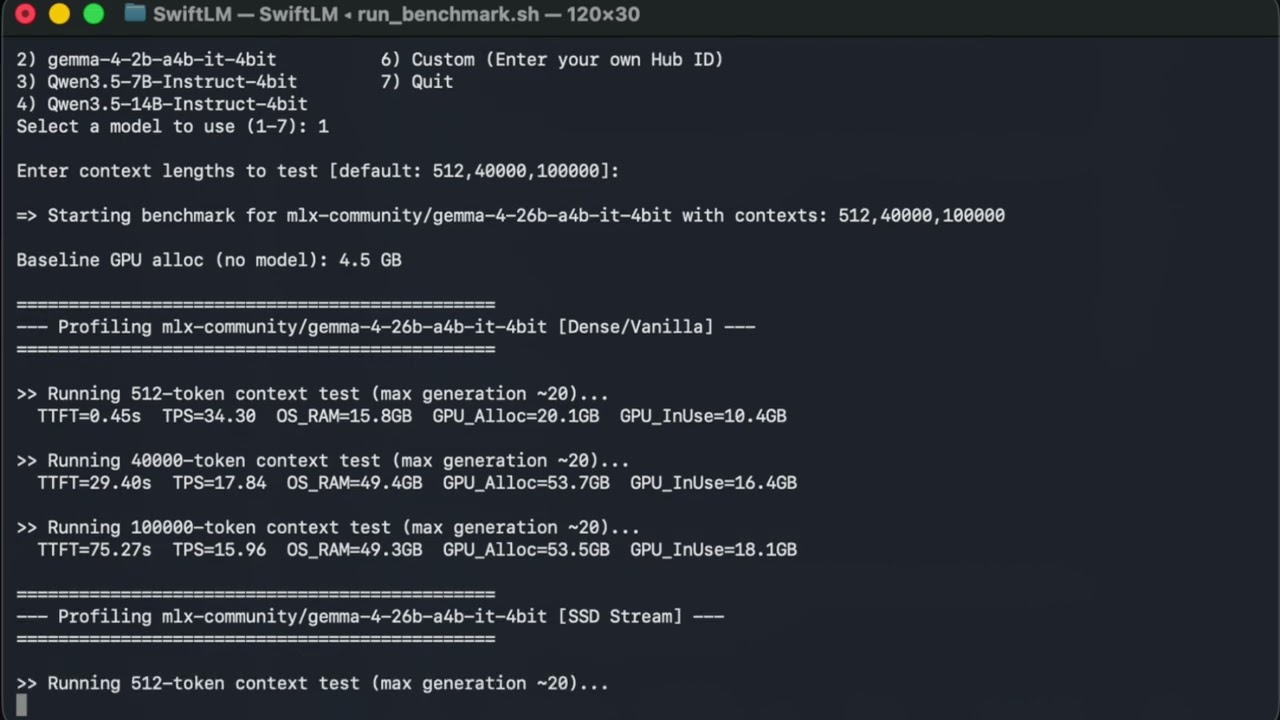
In this demonstration, we showcase SwiftLM: our 100% native Metal & Swift automated inference engine serving an OpenAI-compatible API without any Python overhead.
We walk through extreme context bounds and memory benchmarking across the Apple Silicon family (from M1 8GB Mac Minis to M5 Pro 64GB MacBook Pros).
Key Technologies Showcased in this Demo:
⚡️ Native Apple Silicon Context: Full API integration compiled into a single binary.
🗜️ TurboQuant (KV Cache Compression): Achieving a 3.5x compression matrix on the fly using a hybrid hardware-accelerated/V3 Lloyd-Max codebook. This fits the massive 100K token context window seamlessly.
💾 SSD Expert Streaming (Zero-Copy): Safely bypass macOS Watchdog kernel panics by streaming MoE Expert Layers directly from the NVMe SSD into the Metal GPU command buffer without trashing Unified RAM.
With these architectures, a massive 26B parameter model runs efficiently at just 4.6GB of active RAM on an 8GB machine, or handles massive 100K token limits strictly within 33.3GB instead of exceeding 64GB.
🔗 Explore the code & run the benchmarks yourself: GitHub Repo: https://github.com/SharpAI/SwiftLM
📱 Don't forget to check out our companion Aegis Buddy iOS App to infer local models natively on your iPhone & iPad!
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: