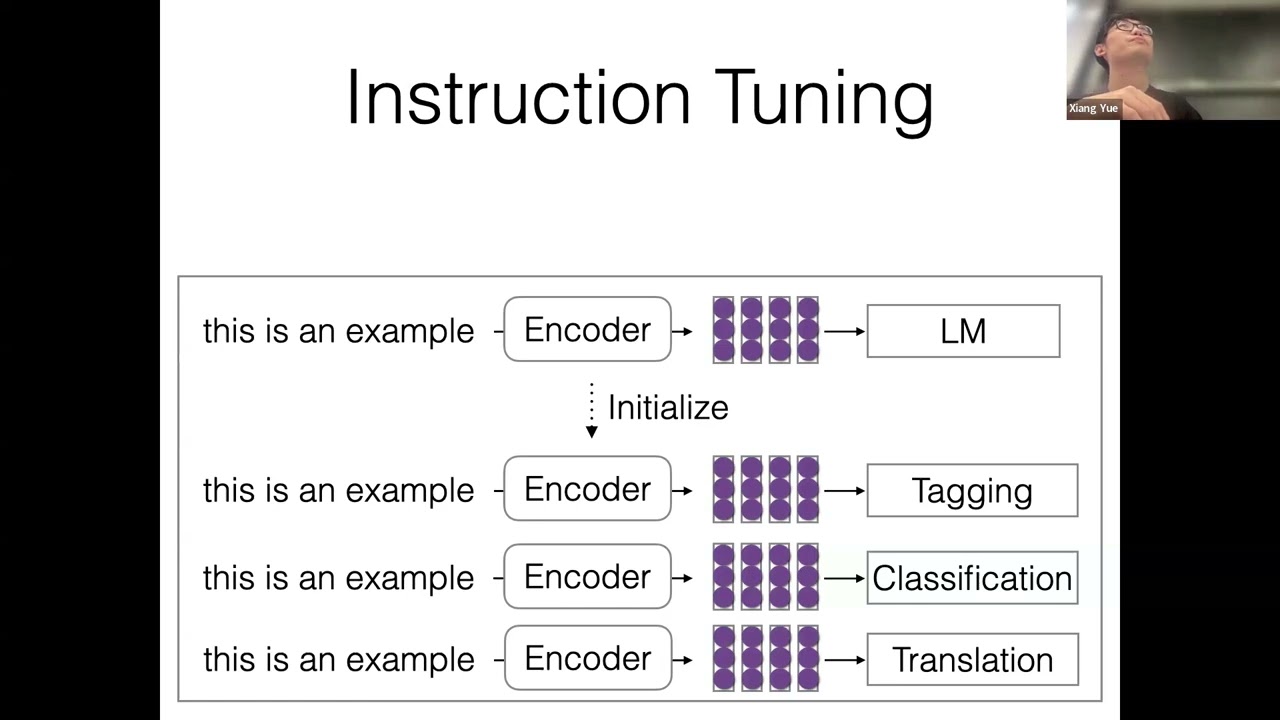
【S4E8】Guardian of Trust in Language Models: Automatic Jailbreak and Systematic Defense
Автор: The AI Talks
Загружено: 2024-05-02
Просмотров: 93
Описание:
#artificialintelligence #aisafety #computervision
ABS: Large Language Models (LLMs) excel in Natural Language Processing (NLP) with human-like text generation, but the misuse of them has raised a significant concern. In this talk, we introduce an innovative system designed to address these challenges. Our system leverages LLMs to play different roles, simulating various user personas to generate "jailbreaks" – prompts that can induce LLMs to produce outputs contrary to ethical standards or specific guidelines. Utilizing a knowledge graph, our method efficiently creates new jailbreaks, testing the LLMs' adherence to governmental and ethical guidelines. Empirical validation on diverse models, including Vicuna-13B, LongChat-7B, Llama-2-7B, and ChatGPT, has demonstrated its efficacy. The system's application extends to Visual Language Models, highlighting its versatility in multimodal contexts.
The second part of our talk shifts focus to defensive strategies against such jailbreaks. Recent studies have uncovered various attacks that can manipulate LLMs, including manual and gradient-based jailbreaks. Our work delves into the development of robust prompt optimization as a novel defense mechanism, inspired from principled solutions from trustworthy machine learning. This approach involves system prompts – parts of the input text inaccessible to users – and aims to counter both manual and gradient-based attacks effectively. Despite current methods, adaptive attacks like GCG remain a challenge, necessitating a formalized defensive objective. Our research proposes such an objective and demonstrates how robust prompt optimization can enhance the safety of LLMs, safeguarding against realistic threat models and adaptive attacks.
Bio: Haohan Wang is an assistant professor in the School of Information Sciences at the University of Illinois Urbana-Champaign. His research focuses on the development of trustworthy machine learning methods for computational biology and healthcare applications. In his work, he uses statistical analysis and deep learning methods, with an emphasis on data analysis using methods least influenced by spurious signals. Wang earned his PhD in computer science through the Language Technologies Institute of Carnegie Mellon University. He is also an organizer of Trustworthy Machine Learning Initiative.
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:









![[S5E3] Масштабирование за пределами авторегрессии: масштабирование порядка как новый путь к общем...](https://imager.clipsaver.ru/ZIOQT4DUBkY/max.jpg)




![[S5E2] Video Models Are Zero-Shot Learners and Reasoners | Thaddäus Wiedemer | Google Deepmind](https://imager.clipsaver.ru/lPxfeTwimAk/max.jpg)