Applied Deep Learning – Class 44 | Multi Head Attention
Автор: gened
Загружено: 2026-02-19
Просмотров: 3
Описание:
In this session of Applied Deep Learning, we dive into Multi-Head Attention — an extension of self-attention that overcomes its limitations and enables richer contextual learning.
This lecture focuses on theory, explaining both the reasoning behind multi-head attention and how it addresses the drawbacks of single-head self-attention.
📚 In this lecture, we cover:
🔹 What is Multi-Head Attention
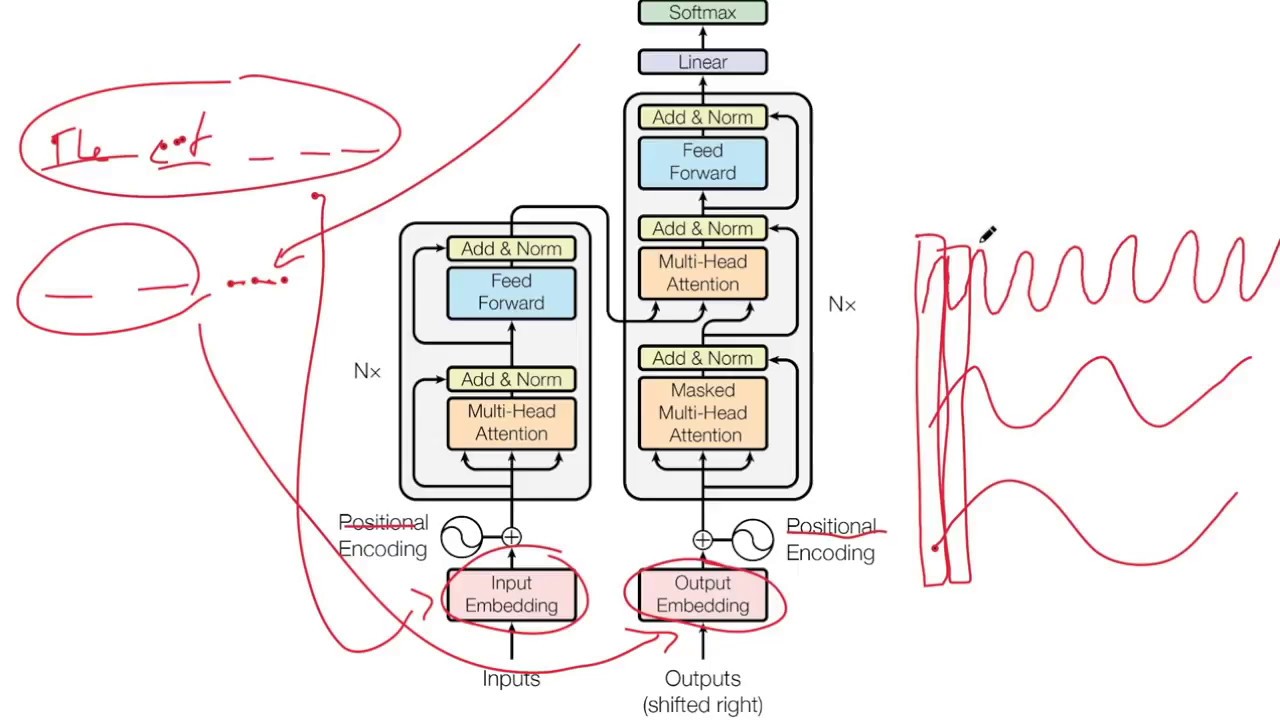
Learn how the Transformer splits self-attention into multiple “heads” to capture different aspects of semantic relationships.
🔹 Limitations of Single-Head Attention
We explain why a single attention head can miss diverse patterns:
✔ Limited focus on only a single representation subspace
✔ Insufficient modeling of multiple context patterns
✔ Less expressive power for complex language structures
🔹 How Multi-Head Helps
✔ Multiple attention heads attend to different parts of the sentence
✔ Helps capture syntactic and semantic features simultaneously
✔ Allows the model to learn richer, varied contextual relations
🔹 Intuition Behind Parallel Heads
We explain how queries, keys, and values are independently projected into multiple subspaces and how their outputs are concatenated and recombined.
This session is essential if you’re preparing for Transformers, BERT, GPT, or advanced NLP architectures, as Multi-Head Attention is a core building block.
📂 Notebook Link:
https://github.com/GenEd-Tech/Applied...
👍 Like, Share & Subscribe for more AI, Deep Learning & NLP content
💬 Comment if you want the next session on Transformer Encoder & Decoder Blocks Explained
#DeepLearning #MultiHeadAttention #SelfAttention #Transformer #NLP #MachineLearning #AI #AppliedDeepLearning
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: