Lecture 1, 2025, Course overview: RL and DP, AlphaZero, deterministic DP, examples, applications
Автор: Dimitri Bertsekas
Загружено: 2025-01-16
Просмотров: 7110
Описание:
Slides, class notes, and related textbook material at https://web.mit.edu/dimitrib/www/RLbo...
This site also contains complete PDF of related textbooks by Bertsekas:
"A Course in Reinforcement Learning", 2nd edition, 2025
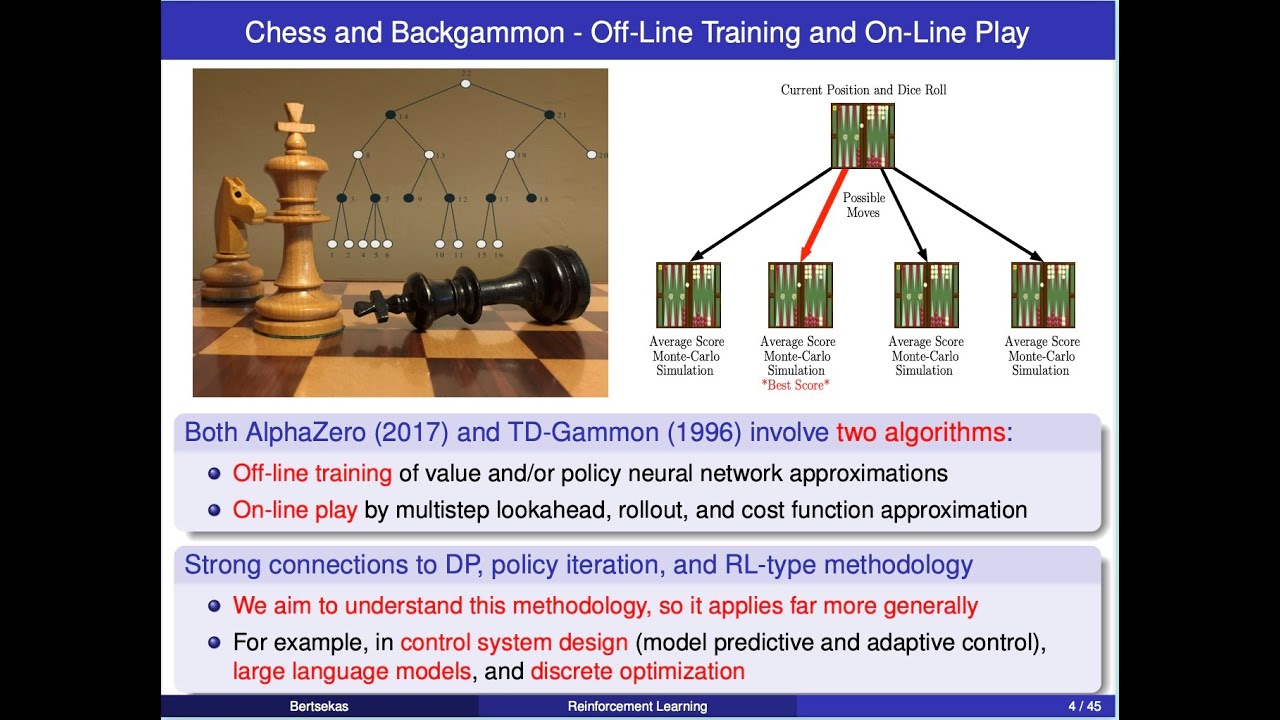
"Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control," 2022
"Abstract Dynamic Programming", 3rd edition, 2022
"Rollout, Policy Iteration, and Distributed Reinforcement Learning," 2020
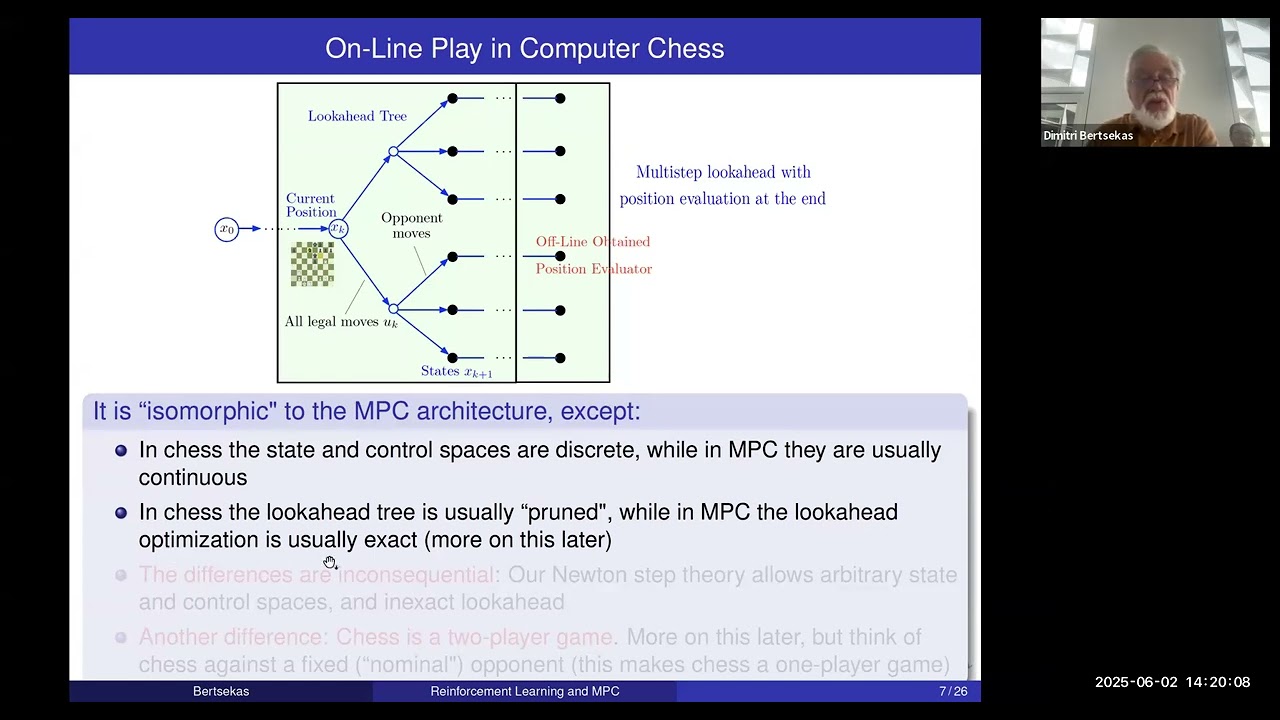
Lecture Content: Course overview, AlphaZero, off-line training, on-line play, relation to Newton's method. Exact and approximate dynamic programming for deterministic problems, discrete optimization, model predictive and adaptive control, large language models via dynamic programming, approximation in value space and reinforcement learning
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: