Объяснение Muon: первый настоящий конкурент Adam
Автор: Tales Of Tensors
Загружено: 2026-06-27
Просмотров: 1155
Описание:
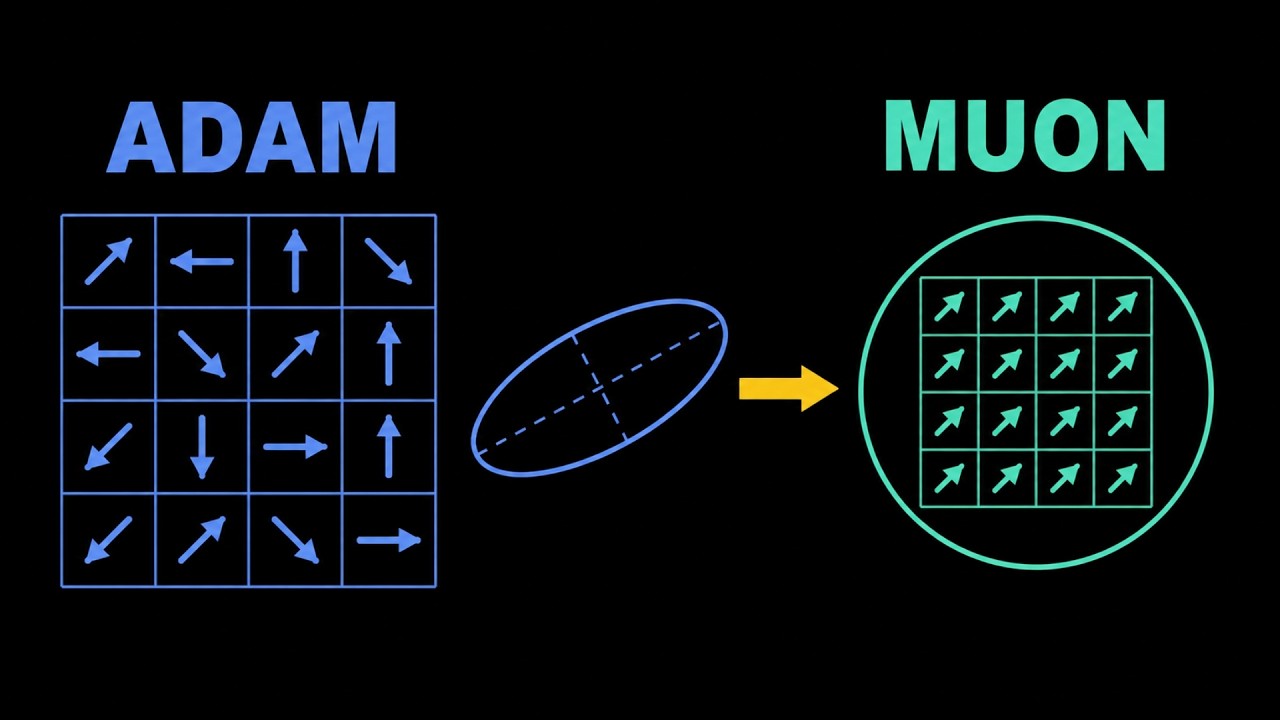
AdamW почти десять лет был оптимизатором по умолчанию для обучения больших нейронных сетей. Но новый оптимизатор под названием Muon может стать его первым серьезным конкурентом.
В этом видео мы наглядно объясним, как работает оптимизатор Muon, чем он отличается от Adam и AdamW, и почему исследователи обращают на него внимание при обучении больших языковых моделей. Вместо того чтобы обрабатывать каждый вес независимо, Muon рассматривает матрицы весов геометрически. Он ортогонализирует обновление момента, изменяет спектр сингулярных значений и направляет обновления обучения в более полезные направления.
Мы разберем основную идею ортогонализации момента, итерации Ньютона-Шульца, полярных факторов и почему Muon может быть более эффективным с точки зрения вычислительных ресурсов, чем AdamW. Мы также объясним подвох: почему обычный Muon может дестабилизировать слои внимания на граничном уровне и как QK-Clip превращает его в MuonClip, делая его более стабильным для обучения больших языковых моделей.
Темы видео:
Почему AdamW стал оптимизатором по умолчанию
Слепое пятно Adam при работе с матричными весами
Сингулярные значения, SVD и матричная геометрия
Как Muon ортогонализирует обновления момента
Визуальное объяснение итерации Ньютона-Шульца
Почему Muon может сократить вычислительные затраты на обучение
Почему логиты внимания могут резко возрасти с помощью Muon
Объяснение QK-Clip и MuonClip
Почему Muon важен для будущего обучения LLM
Если вас интересует обучение LLM, оптимизаторы, архитектура трансформеров, AdamW, Muon, Ньютон-Шульц, законы масштабирования и передовые методы обучения ИИ, это видео даст вам визуальное объяснение одной из самых интересных идей оптимизаторов в современном глубоком обучении.
Оптимизатор Muon
Объяснение Muon
Объяснение оптимизатора Muon
AdamW против Muon
Adam против Muon
Оптимизатор Adam
Оптимизатор AdamW
Оптимизатор LLM
Оптимизатор обучения LLM
Оптимизатор глубокого обучения
Оптимизатор нейронных сетей
Оптимизатор ИИ
Оптимизатор трансформации
Обучение больших языковых моделей
Обучение LLM
Обучение больших языковых моделей
Как обучаются LLM
Объяснение оптимизатора
Объяснение AdamW
MuonClip
Объяснение MuonClip
QK-Clip
Объяснение QK Clip
Логиты внимания
Нестабильность внимания
Обучение LLM на границе
Kimi K2 Muon
Moonlight Muon
Moonshot AI Muon
Итерация Ньютона-Шульца
Итерация Ньютона-Шульца
Ортогонализация импульса
Ортогонализованный импульс
Полярный фактор
Сингулярное значение разложение
Объяснение SVD
сингулярные значения
геометрия матрицы
веса матрицы
быстрое обучение LLM
вычислительно эффективное обучение
вычисления для обучения
законы масштабирования
законы масштабирования LLM
ИИ на границе Парето
Ядро Megatron Muon
Ядро NVIDIA Megatron
обучение трансформеров
объяснение глубокого обучения
объяснение машинного обучения
объяснение исследований в области ИИ
объяснение больших языковых моделей
современное обучение ИИ
будущее LLM
слепое пятно Адама
Muon против AdamW
оптимизатор для трансформеров
обучение в масштабе
стабильность обучения LLM
пики потерь
обрезание ключей запроса
норма QK
многоголовое латентное внимание
внимание MLA
модели ИИ на границе
объяснение обучения ИИ
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: