Семантическое кэширование с использованием Valkey и Redis: снижение затрат и задержки LLM — Марти...
Автор: Percona
Загружено: 2026-01-23
Просмотров: 599
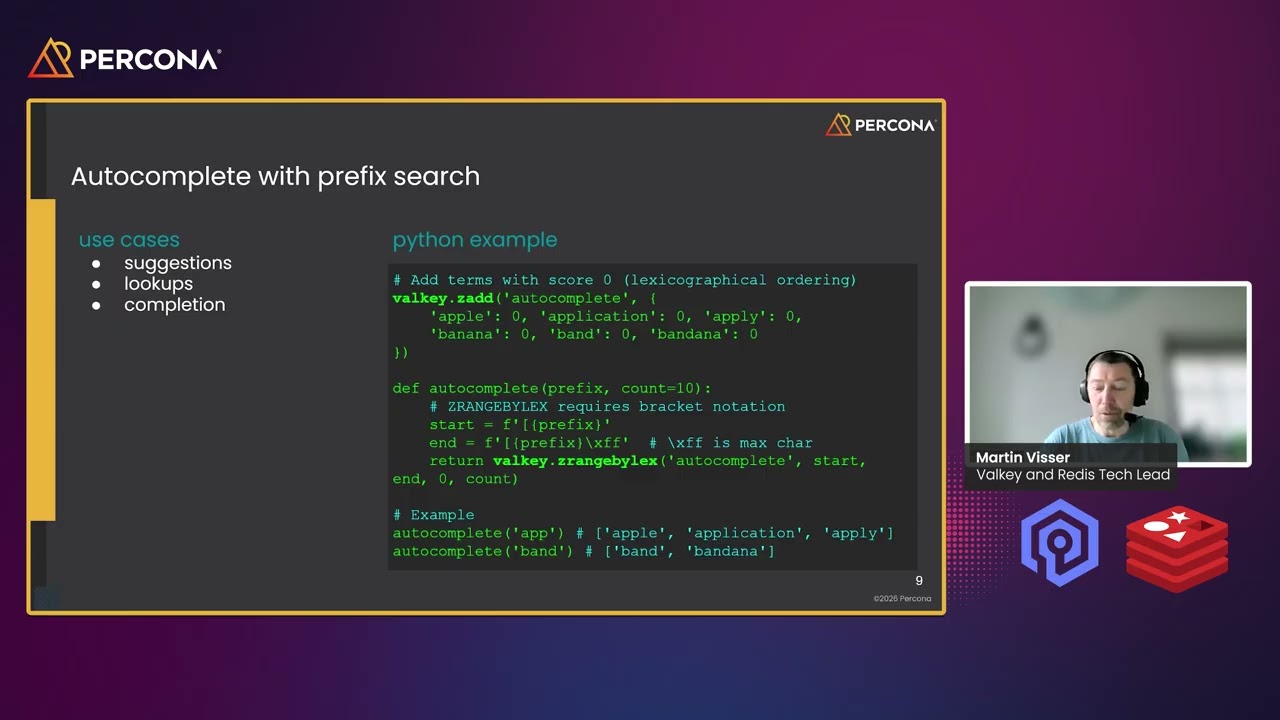
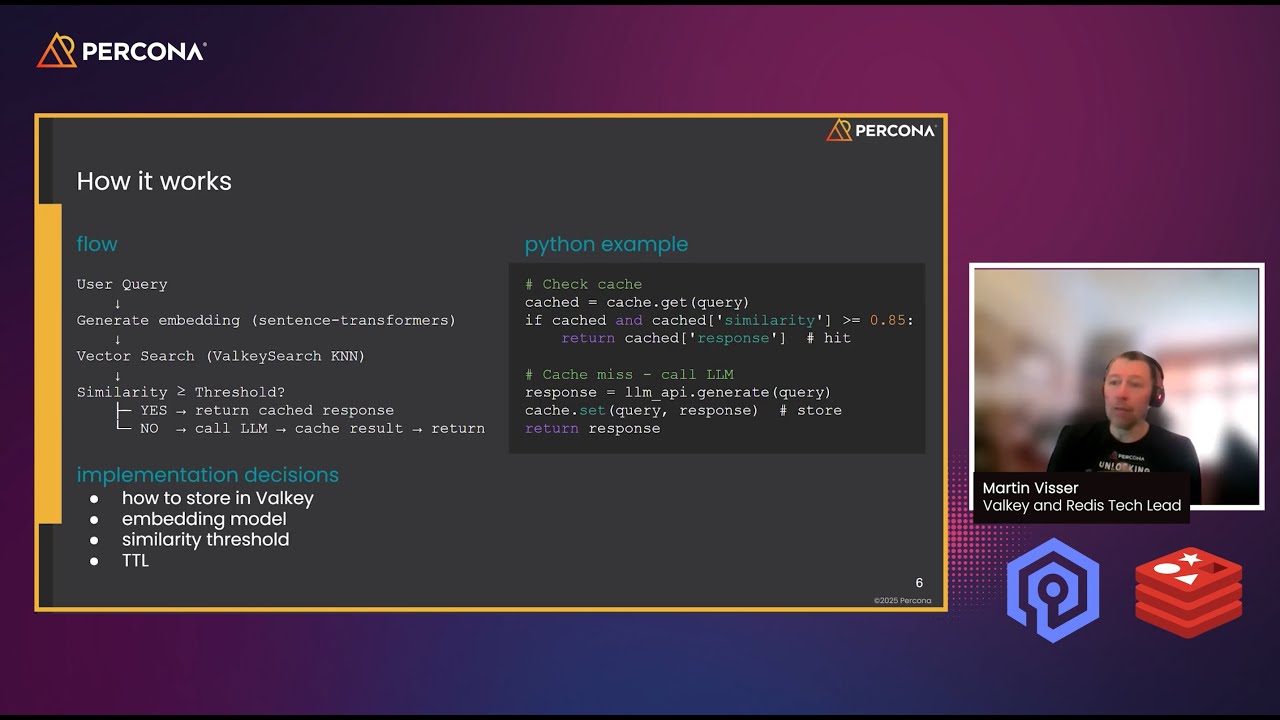
Описание: В этой презентации объясняется, как семантическое кэширование может значительно снизить стоимость и задержку приложений, использующих большие языковые модели (LLM), за счет повторного использования значимых похожих ответов вместо точных совпадений. Используя Valkey и Redis в качестве векторных баз данных, в ней рассматривается, как встраивания, пороговые значения сходства и TTL работают вместе для эффективного кэширования ответов LLM. Доклад включает в себя практические архитектурные решения, компромиссы в конфигурации, сравнение затрат и реальную демонстрацию того, как семантическое кэширование может сократить использование LLM до 60% при одновременном улучшении времени отклика.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: