VideoConviction: Multimodal AI Benchmark for Stock Recommendations (AI Narration)
Автор: Michael Galarnyk
Загружено: 2026-03-05
Просмотров: 34
Описание:
This video presents an AI-narrated walkthrough of our KDD 2025 paper:
VideoConviction: A Multimodal Benchmark for Human Conviction and Stock Market Recommendations.
The narration is generated using a speech model fine-tuned on my own audio recordings. The code for the AI narration pipeline will be released later.
Paper:
https://arxiv.org/abs/2507.08104
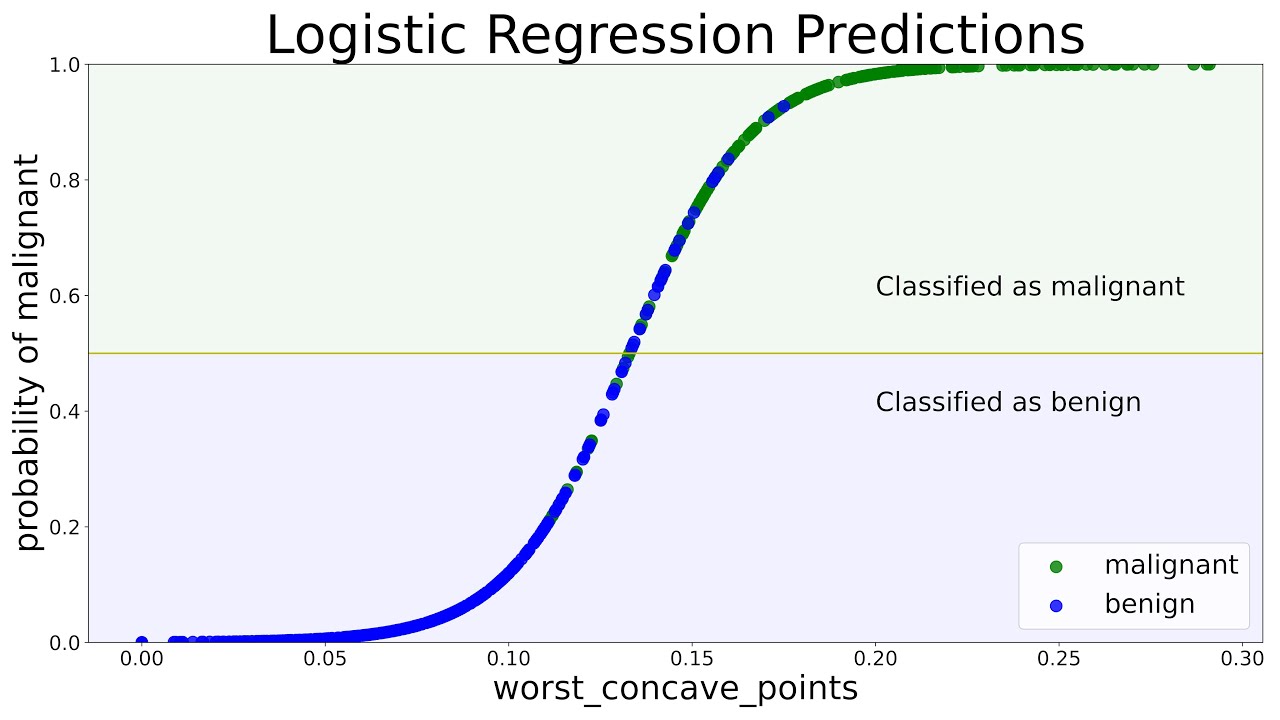
VideoConviction studies how financial influencers ("finfluencers") recommend stocks on YouTube and how multimodal signals such as tone, delivery style, and facial expressions affect perceived investment conviction.
ABSTRACT
Social media has amplified the reach of financial influencers known as "finfluencers," who share stock recommendations on platforms like YouTube. Understanding their influence requires analyzing multimodal signals like tone, delivery style, and facial expressions, which extend beyond text-based financial analysis. We introduce VideoConviction, a multimodal dataset with 6,000+ expert annotations, produced through 457 hours of human effort, to benchmark multimodal large language models (MLLMs) and text-based large language models (LLMs) in financial discourse.
Our results show that while multimodal inputs improve stock ticker extraction (e.g., extracting Apple's ticker AAPL), both MLLMs and LLMs struggle to distinguish investment actions and conviction — the strength of belief conveyed through confident delivery and detailed reasoning — often misclassifying general commentary as definitive recommendations.
While high-conviction recommendations perform better than low-conviction ones, they still underperform the S&P 500 index fund. An inverse strategy — betting against finfluencer recommendations — outperforms the S&P 500 by 6.8% in annual returns but carries greater risk (Sharpe ratio of 0.41 vs. 0.65).
Our benchmark enables evaluation across multiple multimodal tasks and compares model performance on both full videos and segmented video inputs, enabling deeper research on multimodal financial reasoning.
ACKNOWLEDGEMENTS
• Suman Debnath (Anyscale) for the open-source Ray tutorial that helped enable the fine-tuning setup
• Dell Technologies for providing a Dell Pro Max workstation with an NVIDIA RTX PRO 6000 GPU
• Madecraft for providing the LinkedIn Learning audio recordings used to train the narration model
Coauthors:
Veer Kejriwal
Yash Bhardwaj
Nicholas W. Meyer
Anand Krishnan
Sudheer Chava
Georgia Tech Financial Services Innovation Lab
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: