Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning
Автор: AITech_Trends
Загружено: 2025-12-18
Просмотров: 3
Описание:
In this video, we break down the latest research paper “Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning.”
🔍 What’s Inside:
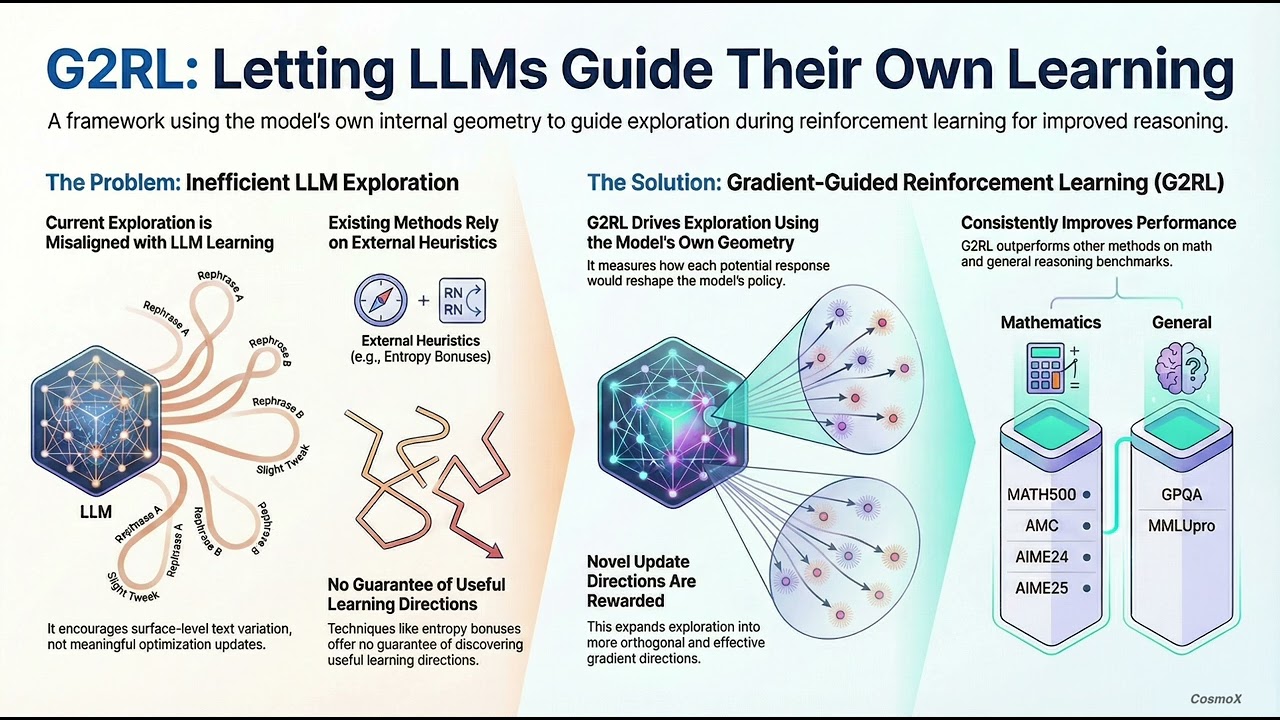
• Current RL exploration methods used in large language models (LLMs) often rely on heuristic signals like entropy bonuses, which may not align with how models actually learn.
• G2RL (Gradient-Guided Reinforcement Learning) proposes a new way to drive exploration based on the model’s own gradient geometry, creating more meaningful update directions during training.
• Experiments show improvements over typical RL approaches on reasoning benchmarks including math and general reasoning tests.
🎯 We explain the idea behind G2RL, why it matters, and how it can enhance reasoning capabilities in LLMs — all made easy to understand.
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке:



















