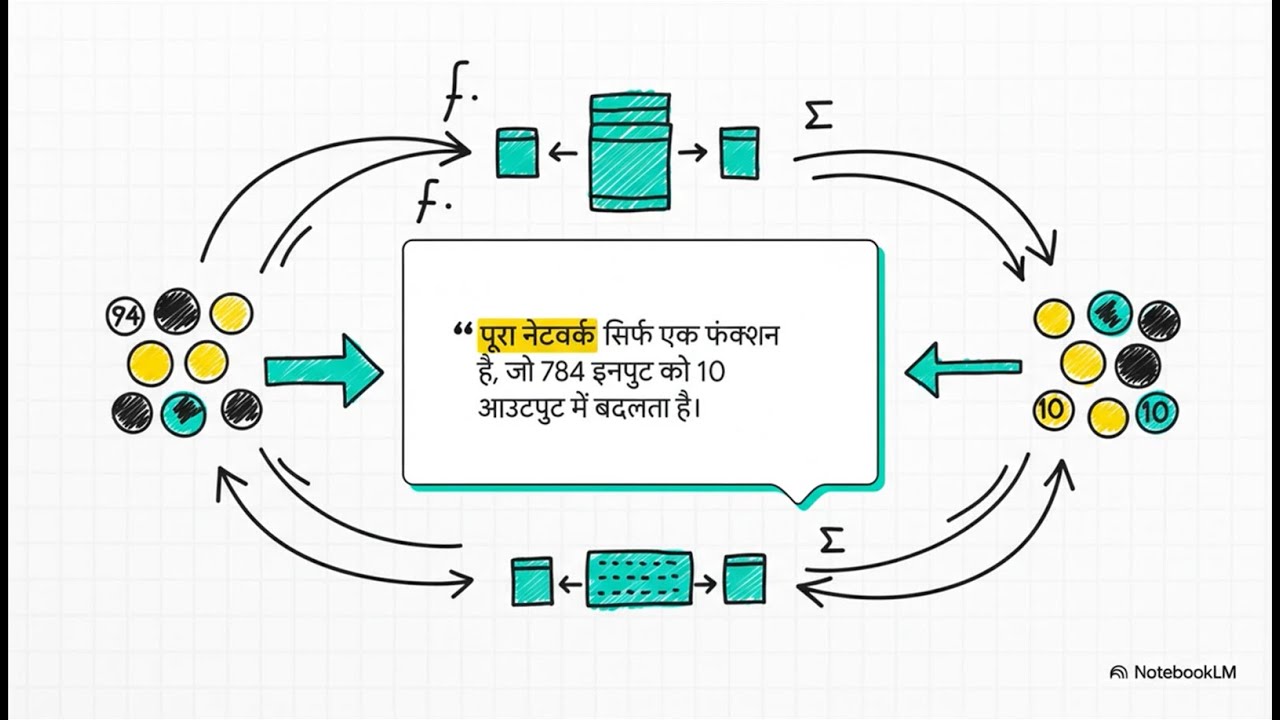
How AI Becomes Human-Like | Fine-Tuning & RLHF Explained In Hindi | Chapter 8
Автор: Neural Nexus
Загружено: 2026-02-03
Просмотров: 10
Описание:
A Neural Network can predict the next word, but how does it learn to follow instructions or have a conversation? The secret is in the final polish: Reinforcement Learning from Human Feedback (RLHF).
In this 8th episode of Neural Nexus, we explore the training process that turned a raw "Titan" into ChatGPT. We go beyond the initial "pre-training" to see how human labels and rewards actually shape the behavior of the model.
In this video, we break down:
The Supervised Phase: How AI learns from high-quality human examples.
The Reward Model: Understanding how we teach a computer to "score" its own answers based on human preferences.
Proximal Policy Optimization (PPO): A simple explanation of the algorithm that pushes the AI to be more helpful and less harmful.
The Alignment Problem: Why it’s so difficult (and important) to make sure AI values match human values.
Conversational Flow: How these techniques allow for the multi-turn dialogues we see in AI Agents today.
This is the bridge between a "calculator" and a "collaborator."
🔔 Subscribe to Neural Nexus as we approach the Final Frontier: AGI!
#RLHF #FineTuning #ArtificialIntelligence #ChatGPT #NeuralNexus #AIEthics #MachineLearningHindi #TechEducation #HowAILearns
Повторяем попытку...

Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: