Deploy DiffusionGemma on GPU Cloud for 1,400+ Tokens Per Second
Автор: Hyperstack
Загружено: 2026-06-22
Просмотров: 92
Описание:
Deploy Google DeepMind's DiffusionGemma on the Hyperstack GPU cloud in this step-by-step tutorial. Learn how to run this high-speed diffusion language model on a single NVIDIA H100 using vLLM.
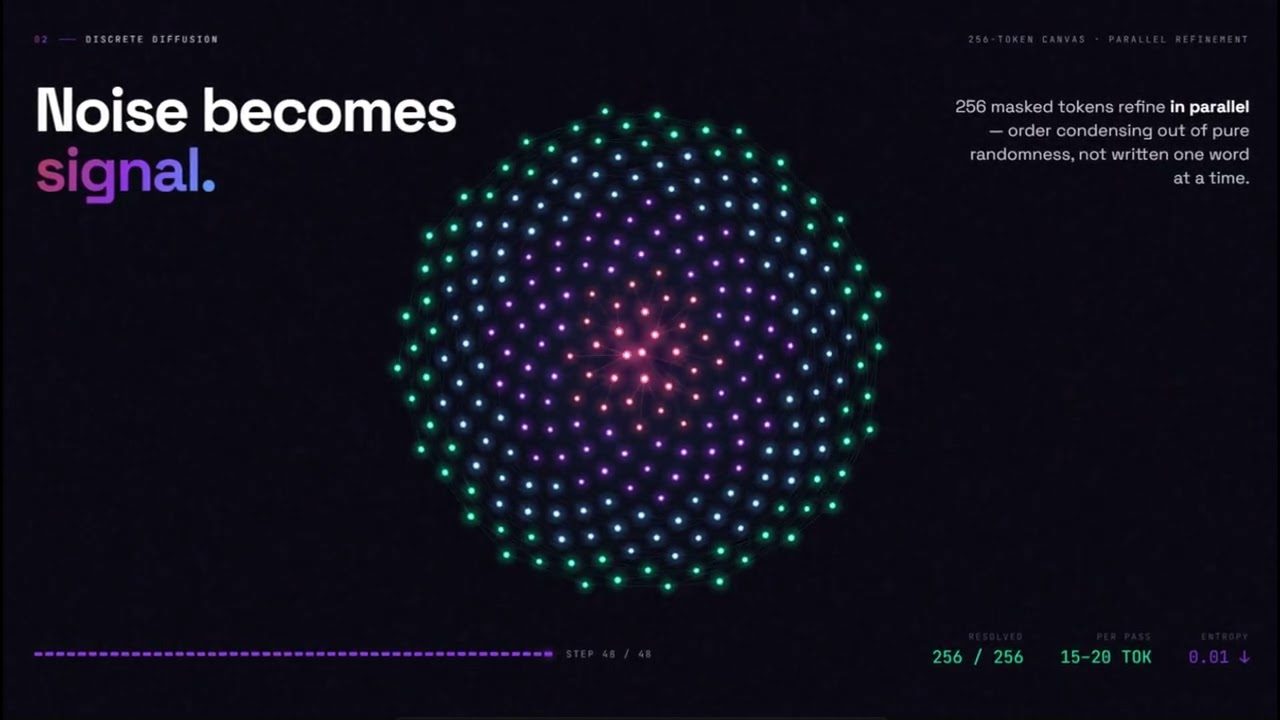
DiffusionGemma is a Mixture-of-Experts model with 25.2B total parameters and just 3.8B activated during inference. It uses discrete diffusion to denoise a 256-token generation canvas per diffusion step in parallel, delivering 1,400+ tokens per second on a single NVIDIA H100 with the Entropy-Bounded sampler, roughly 4x faster than autoregressive models.
In this tutorial, you'll learn:
What DiffusionGemma is and how its discrete diffusion architecture works
How to provision a single NVIDIA H100-80GB PCIe VM on Hyperstack
How to launch a vLLM inference server with the Entropy-Bounded diffusion sampler
How to query the OpenAI-compatible API for text generation use cases
How to benchmark real-world throughput on your own hardware
The model supports a 256K token context window, multimodal input (text, image and video) and delivers 1,400+ tokens/sec on NVIDIA H100, ideal for high-volume chat, code generation and document processing workloads.
Full tutorial on Hyperstack Blog: https://eu1.hubs.ly/H0wljyw0
Get started on Hyperstack: https://eu1.hubs.ly/H0wlfz_0
If this helped, like and subscribe for more GPU cloud and LLM deployment tutorials!
Повторяем попытку...
Доступные форматы для скачивания:
Скачать видео
-
Информация по загрузке: